版本:3cda49cfaa8556b73277ccd7e75952f0f2de2d74(Thu Jul 10 13:27:41 2025 +0200)
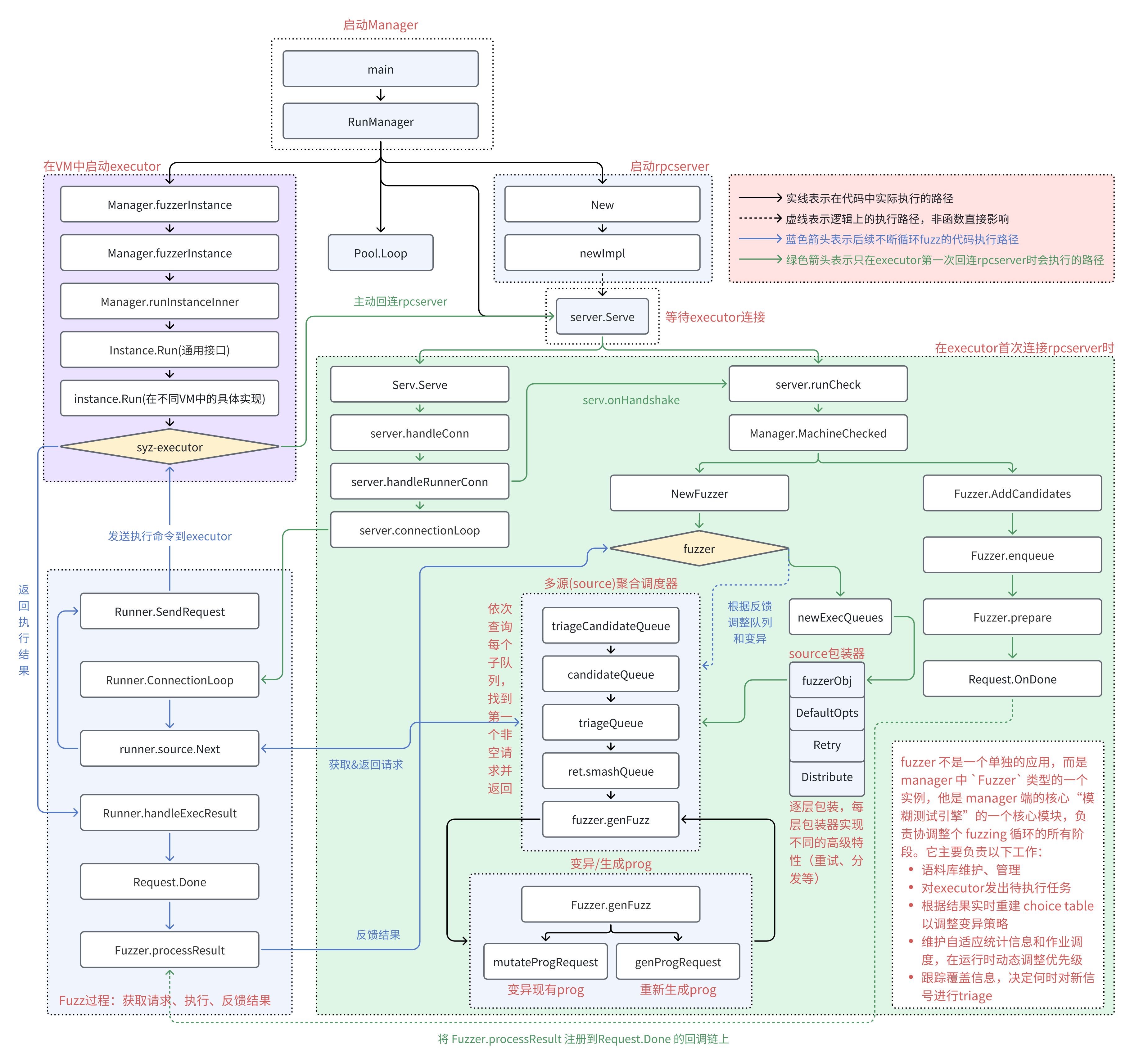
# 入口
# RunManager
syzkaller 的调度链条从位于 syz-manager/manager.go 的 RunManager 函数开始,主要完成如下功能:
- 创建 VM 调度器
- 创建 RPC 服务
- 创建 HTTP 站点
func RunManager(mode *Mode, cfg *mgrconfig.Config) { | |
var vmPool *vm.Pool | |
if !cfg.VMLess { | |
var err error | |
// 创建 VM 池 | |
vmPool, err = vm.Create(cfg, *flagDebug) | |
if err != nil { | |
log.Fatalf("%v", err) | |
} | |
defer vmPool.Close() | |
} | |
// 确保工作目录存在。 | |
osutil.MkdirAll(cfg.Workdir) | |
// 构建崩溃报告器,后续用于解析内核崩溃和分类 | |
reporter, err := report.NewReporter(cfg) | |
if err != nil { | |
log.Fatalf("%v", err) | |
} | |
mgr := &Manager{ | |
cfg: cfg, | |
mode: mode, | |
vmPool: vmPool, | |
corpusPreload: make(chan []fuzzer.Candidate), | |
target: cfg.Target, | |
sysTarget: cfg.SysTarget, | |
reporter: reporter, | |
crashStore: manager.NewCrashStore(cfg), | |
crashTypes: make(map[string]bool), | |
disabledHashes: make(map[string]struct{}), | |
memoryLeakFrames: make(map[string]bool), | |
dataRaceFrames: make(map[string]bool), | |
fresh: true, | |
externalReproQueue: make(chan *manager.Crash, 10), | |
crashes: make(chan *manager.Crash, 10), | |
saturatedCalls: make(map[string]bool), | |
reportGenerator: manager.ReportGeneratorCache(cfg), | |
} | |
if *flagDebug { | |
mgr.cfg.Procs = 1 | |
} | |
// HTTP 服务外壳,仅当 cfg.HTTP 非空才真正监听 | |
mgr.http = &manager.HTTPServer{ | |
// Note that if cfg.HTTP == "", we don't start the server. | |
Cfg: cfg, | |
StartTime: time.Now(), | |
CrashStore: mgr.crashStore, | |
} | |
// 初始化统计计数器 | |
mgr.initStats() | |
if mgr.mode.LoadCorpus { | |
go mgr.preloadCorpus() // 在后台预载种子 | |
} else { | |
close(mgr.corpusPreload) | |
} | |
// Create RPC server for fuzzers. | |
// 收集 RPC 层指标 | |
mgr.servStats = rpcserver.NewStats() | |
rpcCfg := &rpcserver.RemoteConfig{ | |
Config: mgr.cfg, | |
Manager: mgr, | |
Stats: mgr.servStats, | |
Debug: *flagDebug, | |
} | |
// 构建 RPC 服务端 | |
mgr.serv, err = rpcserver.New(rpcCfg) | |
if err != nil { | |
log.Fatalf("failed to create rpc server: %v", err) | |
} | |
// 绑定端口 | |
if err := mgr.serv.Listen(); err != nil { | |
log.Fatalf("failed to start rpc server: %v", err) | |
} | |
ctx := vm.ShutdownCtx() | |
// 在协程中开始处理 fuzzer 的注册、同步、拉取任务等 | |
go func() { | |
err := mgr.serv.Serve(ctx) | |
if err != nil { | |
log.Fatalf("%s", err) | |
} | |
}() | |
log.Logf(0, "serving rpc on tcp://%v", mgr.serv.Port()) | |
// 创建 Dashboard 客户端并连接 | |
if cfg.DashboardAddr != "" { | |
opts := []dashapi.DashboardOpts{} | |
if cfg.DashboardUserAgent != "" { | |
opts = append(opts, dashapi.UserAgent(cfg.DashboardUserAgent)) | |
} | |
dash, err := dashapi.New(cfg.DashboardClient, cfg.DashboardAddr, cfg.DashboardKey, opts...) | |
if err != nil { | |
log.Fatalf("failed to create dashapi connection: %v", err) | |
} | |
mgr.dashRepro = dash | |
if !cfg.DashboardOnlyRepro { | |
mgr.dash = dash | |
} | |
} | |
// 初始化外部资产存储,用于保存 repro 程序、日志、报告附件等 | |
if !cfg.AssetStorage.IsEmpty() { | |
mgr.assetStorage, err = asset.StorageFromConfig(cfg.AssetStorage, mgr.dash) | |
if err != nil { | |
log.Fatalf("failed to init asset storage: %v", err) | |
} | |
} | |
// 配置基准测试路径,而非正常 fuzz | |
if *flagBench != "" { | |
mgr.initBench() | |
} | |
// 定期上报健康状态与统计 | |
go mgr.heartbeatLoop() | |
if mgr.mode != ModeSmokeTest { | |
osutil.HandleInterrupts(vm.Shutdown) // 捕获信号并触发全局 vm.Shutdown | |
} | |
// 无 VM 模式,需要手动启动 syz-executor | |
if mgr.vmPool == nil { | |
log.Logf(0, "no VMs started (type=none)") | |
log.Logf(0, "you are supposed to start syz-executor manually as:") | |
log.Logf(0, "syz-executor runner local manager.ip %v", mgr.serv.Port()) | |
<-vm.Shutdown | |
return | |
} | |
// 有 Vm 模式:调度和复现 | |
mgr.pool = vm.NewDispatcher(mgr.vmPool, mgr.fuzzerInstance) // Dispatcher 负责把 fuzzer 实例分配到 VM,并处理 VM 生命周期与任务派发 | |
mgr.http.Pool = mgr.pool | |
reproVMs := max(0, mgr.vmPool.Count()-mgr.cfg.FuzzingVMs) // 保留 cfg.FuzzingVMs 做在线 fuzz,其余空闲给复现用 | |
// 复现流水线消费 crashes/externalReproQueue,在独立 VM 上尝试最小化与稳定复现。 | |
mgr.reproLoop = manager.NewReproLoop(mgr, reproVMs, mgr.cfg.DashboardOnlyRepro) | |
mgr.http.ReproLoop = mgr.reproLoop // 供界面触发重试、取消 | |
mgr.http.TogglePause = mgr.pool.TogglePause // 供界面一键暂停 / 恢复 fuzz | |
if mgr.cfg.HTTP != "" { | |
// 启动 Web UI/API,展示统计、队列、崩溃与复现状态。 | |
go func() { | |
err := mgr.http.Serve(ctx) | |
if err != nil { | |
log.Fatalf("failed to serve HTTP: %v", err) | |
} | |
}() | |
} | |
go mgr.trackUsedFiles() // 清理与跟踪工作目录产物,避免磁盘膨胀 | |
go mgr.processFuzzingResults(ctx) // 汇总 fuzzer 返回的执行结果、覆盖率、崩溃、Input triage 等 | |
mgr.pool.Loop(ctx) // 主阻塞循环。不断调度 VM/fuzzer 实例,直至 ctx 取消 | |
} |
# RPC 服务创建
# New
New(cfg *RemoteConfig) 把 RemoteConfig 组装成可运行的 RPC 服务器 Server
func New(cfg *RemoteConfig) (Server, error) { | |
var pcBase uint64 | |
if cfg.KernelObj != "" { | |
var err error | |
// 解析内核符号基址,用于后续的覆盖率符号化 | |
pcBase, err = cover.GetPCBase(cfg.Config) | |
if err != nil { | |
return nil, err | |
} | |
} | |
// 将 sandbox 配置转为位标志 | |
sandbox, err := flatrpc.SandboxToFlags(cfg.Sandbox) | |
if err != nil { | |
return nil, err | |
} | |
features := flatrpc.AllFeatures // 计算特性位集 | |
if !cfg.Experimental.RemoteCover { | |
features &= ^flatrpc.FeatureExtraCoverage | |
} | |
return newImpl(&Config{ | |
Config: vminfo.Config{ | |
Target: cfg.Target, | |
VMType: cfg.Type, | |
Features: features, | |
Syscalls: cfg.Syscalls, | |
Debug: cfg.Debug, | |
Cover: cfg.Cover, | |
Sandbox: sandbox, | |
SandboxArg: cfg.SandboxArg, | |
}, | |
Stats: cfg.Stats, | |
VMArch: cfg.TargetVMArch, | |
RPC: cfg.RPC, | |
VMLess: cfg.VMLess, | |
// 仅在非 gVisor 时允许 edge 级覆盖率作为反馈信号。 | |
UseCoverEdges: cfg.Experimental.CoverEdges && cfg.Type != targets.GVisor, | |
// 仅对 Linux 目标启用信号过滤;gVisor/Starnix 关闭。 | |
FilterSignal: cfg.Type != targets.GVisor && cfg.Type != targets.Starnix, | |
PrintMachineCheck: true, // 固定为真,打印机器检查结果。 | |
Procs: cfg.Procs, // 执行器并发数 | |
Slowdown: cfg.Timeouts.Slowdown, // 超时放大因子 | |
pcBase: pcBase, // 内核符号基址 | |
localModules: cfg.LocalModules, // 本地内核模块信息,供符号化或过滤 | |
}, cfg.Manager), nil | |
} |
# newImpl
newImpl 组装并返回 RPC 服务器实现 *server ,内含 “机器检查→任务源→执行分发” 的骨架。它不启动任何循环,只做依赖注入与初始数据流搭好。
func newImpl(cfg *Config, mgr Manager) *server { | |
// 用 VMArch 决定位宽与内核地址区间,供超时与覆盖率等计算。 | |
sysTarget := targets.Get(cfg.Target.OS, cfg.VMArch) | |
// 限制执行器并发数,避免超过内置上限。 | |
cfg.Procs = min(cfg.Procs, prog.MaxPids) | |
// 用于握手后探测:可用 syscalls、特性位、内核文件信息等 | |
checker := vminfo.New(&cfg.Config) | |
// 占位源。启动时还不知道启用的 syscalls,由机器检查结果填充。后续在 MachineChecked 中以 baseSource.Store (newSource) 替换为真实源(如 fuzz 源)。 | |
baseSource := queue.DynamicSource(checker) | |
return &server{ | |
cfg: cfg, // 配置 | |
mgr: mgr, // 回调接口 | |
target: cfg.Target, // 目标平台 | |
sysTarget: sysTarget, // 目标平台的体系结构相关信息 | |
timeouts: sysTarget.Timeouts(cfg.Slowdown), // 基于体系结构的超时设置 | |
runners: make(map[int]*Runner), // 活跃的 runner/VM 列表 | |
checker: checker, // 机器检查器 | |
baseSource: baseSource, // 原子可替换的任务 / 程序源 | |
//execSource:最终的任务 / 程序源。 | |
// 其底层是 baseSource,但被包装了两层: | |
// Retry (baseSource):若一次执行请求失败,自动重试生成请求。 | |
// Distribute (...):把请求在多 runner/VM 之间均衡分发。 | |
execSource: queue.Distribute(queue.Retry(baseSource)), | |
onHandshake: make(chan *handshakeResult, 1), // 一次性通道,握手完成后推入 | |
// Stats 与 runnerStats:统计指标,包括执行重试、执行器重启、缓冲过小、无任务次数与时长等 | |
// 部分直接复用 queue 里的全局指标 | |
Stats: cfg.Stats, | |
runnerStats: &runnerStats{ | |
statExecRetries: stat.New("exec retries", | |
"Number of times a test program was restarted because the first run failed", | |
stat.Rate{}, stat.Graph("executor")), | |
statExecutorRestarts: stat.New("executor restarts", | |
"Number of times executor process was restarted", stat.Rate{}, stat.Graph("executor")), | |
statExecBufferTooSmall: queue.StatExecBufferTooSmall, | |
statExecs: cfg.Stats.StatExecs, | |
statNoExecRequests: queue.StatNoExecRequests, | |
statNoExecDuration: queue.StatNoExecDuration, | |
}, | |
} | |
} |
# 运行 executor
# Manager.fuzzerInstance
在实例上执行 fuzzerInstance , fuzzerInstance 是调度器在 “一个 VM 实例” 上执行的默认任务。它把该 VM 接入 RPCServer,运行 fuzz,监听崩溃,收尾并把崩溃投递到 mgr.crashes
func (mgr *Manager) fuzzerInstance(ctx context.Context, inst *vm.Instance, updInfo dispatcher.UpdateInfo) { | |
mgr.mu.Lock() | |
// 加锁取 mgr.serv,若为 nil 直接返回。说明正关停 RPCServer,避免新实例接入。 | |
serv := mgr.serv | |
mgr.mu.Unlock() | |
if serv == nil { | |
// We're in the process of switching off the RPCServer. | |
return | |
} | |
// 供 RPC 层向该实例 “注入一次立即执行” 的信号队列。带缓冲,避免阻塞 | |
injectExec := make(chan bool, 10) | |
// 在 RPCServer 侧登记此 VM。绑定实例索引、注入通道和调度更新信息 updInfo | |
serv.CreateInstance(inst.Index(), injectExec, updInfo) | |
// 启动并运行实例,负责引导 VM、启动 syz-executor/syz-fuzzer、处理心跳与日志 | |
rep, vmInfo, err := mgr.runInstanceInner(ctx, inst, injectExec, vm.EarlyFinishCb(func() { | |
// 一旦抓到崩溃,调用 serv.StopFuzzing (inst.Index ()) 来停止 fuzz | |
// 崩溃后内核仍可能继续输出,提前停止 fuzz,减少日志噪声 | |
serv.StopFuzzing(inst.Index()) | |
})) | |
// 采集执行器信息 | |
var extraExecs []report.ExecutorInfo | |
if rep != nil && rep.Executor != nil { | |
extraExecs = []report.ExecutorInfo{*rep.Executor} | |
} | |
// 关闭实例在 RPCServer 的会话 | |
lastExec, machineInfo := serv.ShutdownInstance(inst.Index(), rep != nil, extraExecs...) | |
// 整理报告 | |
if rep != nil { | |
rpcserver.PrependExecuting(rep, lastExec) | |
if len(vmInfo) != 0 { | |
machineInfo = append(append(vmInfo, '\n'), machineInfo...) | |
} | |
rep.MachineInfo = machineInfo | |
} | |
// 上报崩溃 | |
if err == nil && rep != nil { | |
mgr.crashes <- &manager.Crash{ | |
InstanceIndex: inst.Index(), | |
Report: rep, | |
} | |
} | |
// 若运行出错,打印错误信息 | |
if err != nil { | |
log.Logf(1, "VM %v: failed with error: %v", inst.Index(), err) | |
} | |
} |
运行 runInstanceInner ,他负责在一台 VM 上拉起 syz-executor runner ,把它接到本机 RPC 端口,运行到超时或崩溃。三种返回:
rep==nil, err==nil:无崩溃,正常跑满一轮,调用方应重启该 VM 继续循环。rep!=nil, err==nil:捕获到崩溃,返回崩溃报告与机器信息。err!=nil:启动或运行失败(含转发、拷贝、执行失败)。
# Manager.runInstanceInner
Manager.runInstanceInner 负责把 RPC 端口映射到 VM 可访问的地址,然后按需求把 syz-executor 拷贝到 VM 中,然后拼接出执行 syz-executor 命令的字符串并执行。
func (mgr *Manager) runInstanceInner(ctx context.Context, inst *vm.Instance, injectExec <-chan bool, | |
finishCb vm.EarlyFinishCb) (*report.Report, []byte, error) { | |
// 把 manager 的 RPC 端口映射到 client 可达地址 fwdAddr。失败直接报错。 | |
fwdAddr, err := inst.Forward(mgr.serv.Port()) | |
if err != nil { | |
return nil, nil, fmt.Errorf("failed to setup port forwarding: %w", err) | |
} | |
// 若镜像内已内置 syz-executor(ExecutorBin 非空),直接用; | |
// 否则从宿主把 cfg.ExecutorBin 拷入来宾,并返回来宾内路径。拷贝失败报错。 | |
executorBin := mgr.sysTarget.ExecutorBin | |
if executorBin == "" { | |
executorBin, err = inst.Copy(mgr.cfg.ExecutorBin) | |
if err != nil { | |
return nil, nil, fmt.Errorf("failed to copy binary: %w", err) | |
} | |
} | |
// Run the fuzzer binary. | |
start := time.Now() | |
// 在来宾机执行:/path/to/syz-executor runner <vm-index> <manager-host> <manager-port> | |
//executor 会主动连回 RPCServer,领取任务并报告执行状态。 | |
host, port, err := net.SplitHostPort(fwdAddr) | |
if err != nil { | |
return nil, nil, fmt.Errorf("failed to parse manager's address") | |
} | |
cmd := fmt.Sprintf("%v runner %v %v %v", executorBin, inst.Index(), host, port) | |
// 给整次运行的上限时长。到点没崩溃就正常返回 rep=nil | |
ctxTimeout, cancel := context.WithTimeout(ctx, mgr.cfg.Timeouts.VMRunningTime) | |
defer cancel() | |
// 运行并设超时 | |
//mgr.reporter 用于解析内核日志,识别崩溃并构造 *report.Report | |
//vm.InjectExecuting (injectExec):从 injectExec 通道接收 “立刻执行一次” 的注入信号,配合 RPC 控制热触发。 | |
//finishCb(早停回调):一旦识别到崩溃,通知外层停止继续 fuzz,避免污染日志 | |
_, rep, err := inst.Run(ctxTimeout, mgr.reporter, cmd, | |
vm.ExitTimeout, vm.InjectExecuting(injectExec), | |
finishCb, | |
) | |
// 三种返回情况 | |
if err != nil { // 执行器未能启动 / 通信异常 / 命令失败,外层记录错误并重置槽位 | |
return nil, nil, fmt.Errorf("failed to run fuzzer: %w", err) | |
} | |
if rep == nil { // 这轮到时或正常结束,无崩溃;外层会复用此槽位并重启。 | |
log.Logf(0, "VM %v: running for %v, restarting", inst.Index(), time.Since(start)) | |
return nil, nil, nil | |
} | |
vmInfo, err := inst.Info() | |
if err != nil { // 已捕获崩溃(含栈、类型、执行器信息) | |
vmInfo = []byte(fmt.Sprintf("error getting VM info: %v\n", err)) | |
} | |
return rep, vmInfo, nil | |
} |
# Instance.Run
Instance.Run 在一台 VM 里执行一条命令(类似 ssh 执行),同时监控命令输出和内核控制台,识别 oops / 崩溃 / 断连 / 挂起等异常;最后返回截断后的输出、非符号化的崩溃报告(无则为 nil )、以及错误。
// Run runs cmd inside of the VM (think of ssh cmd) and monitors command execution | |
// and the kernel console output. It detects kernel oopses in output, lost connections, hangs, etc. | |
// Returns command+kernel output and a non-symbolized crash report (nil if no error happens). | |
// Accepted options: | |
// - ExitCondition: says which exit modes should be considered as errors/OK | |
// - OutputSize: how much output to keep/return | |
func (inst *Instance) Run(ctx context.Context, reporter *report.Reporter, command string, opts ...any) ( | |
[]byte, *report.Report, error) { | |
exit := ExitNormal | |
var injected <-chan bool | |
var finished func() | |
outputSize := beforeContextDefault | |
// 可选配置 | |
for _, o := range opts { | |
switch opt := o.(type) { | |
case ExitCondition: // 定义哪些退出模式算 “错误 / OK”(如非零返回是否视为错误,或者仅以内核崩溃为错误) | |
exit = opt | |
case OutputSize: // 保留并返回的输出最大字节数(用于日志上下文截断) | |
outputSize = int(opt) | |
case InjectExecuting: // 注入 “正在执行” 的信号通道,runner 在收到信号时可立即标记执行状态,配合超时与状态查询 | |
injected = opt | |
case EarlyFinishCb: // 一旦检测到崩溃征兆可提前回调,通知外层尽快停止进一步 fuzz | |
finished = opt | |
default: | |
panic(fmt.Sprintf("unknown option %#v", opt)) | |
} | |
} | |
// 在 VM 中执行命令 | |
outc, errc, err := inst.impl.Run(ctx, command) | |
if err != nil { | |
return nil, nil, err | |
} | |
// 构建监视器并开始监控 | |
//monitor 负责读 outc/errc、拼接输出、滚动截断、识别心跳 / 执行注入、 | |
// 调用 reporter 解析崩溃、依据 exit 判定终止条件 | |
mon := &monitor{ | |
inst: inst, | |
outc: outc, | |
injected: injected, | |
errc: errc, | |
finished: finished, | |
reporter: reporter, | |
beforeContext: outputSize, | |
exit: exit, | |
lastExecuteTime: time.Now(), | |
} | |
rep := mon.monitorExecution() | |
return mon.output, rep, nil | |
} |
# instance.Run
instance.Run 的实现依赖于具体的 VM 类型,这里给出 Qemu 的实现:它在宿主机上启动一条 ssh 命令去目标 VM 执行 command ,把远端输出并入本地多路复用器,最后返回两个通道: <-chan []byte (输出流)和 <-chan error (进程 / 连接错误)。
func (inst *instance) Run(ctx context.Context, command string) ( | |
<-chan []byte, <-chan error, error) { | |
// 建一对长管道:本进程把子进程的 stdout/stderr 写到 wpipe,自己从 rpipe 读 | |
rpipe, wpipe, err := osutil.LongPipe() | |
if err != nil { | |
return nil, nil, err | |
} | |
// 把 rpipe 注册到 inst.merger(输出合并器),形成统一输出流 | |
inst.merger.Add("ssh", rpipe) | |
// 生成 ssh 基本参数:密钥、端口、端口转发 | |
sshArgs := vmimpl.SSHArgsForward(inst.debug, inst.Key, inst.Port, inst.forwardPort, false) | |
args := strings.Split(command, " ") | |
if bin := filepath.Base(args[0]); inst.target.HostFuzzer && bin == "syz-execprog" { | |
// Weird mode for Fuchsia. | |
// Fuzzer and execprog are on host (we did not copy them), so we will run them as is, | |
// but we will also wrap executor with ssh invocation. | |
// Fuchsia 操作系统特例:fuzzer/execprog 在宿主机跑,executor 在设备上跑, | |
// 这种情况下,需要把 -executor=<path> 改写成通过 ssh 去远端执行 executor。 | |
for i, arg := range args { | |
if strings.HasPrefix(arg, "-executor=") { | |
args[i] = "-executor=" + "/usr/bin/ssh " + strings.Join(sshArgs, " ") + | |
" " + inst.User + "@localhost " + arg[len("-executor="):] | |
} | |
if host := inst.files[arg]; host != "" { | |
args[i] = host | |
} | |
} | |
} else { | |
// 准备 ssh 命令参数,后续用 ssh 在 VM 里面执行 | |
args = []string{"ssh"} | |
args = append(args, sshArgs...) | |
// 远端先 cd 到目标目录,再执行 command | |
args = append(args, inst.User+"@localhost", "cd "+inst.targetDir()+" && "+command) | |
} | |
if inst.debug { | |
log.Logf(0, "running command: %#v", args) | |
} | |
// 拼接成字符串 | |
cmd := osutil.Command(args[0], args[1:]...) | |
cmd.Dir = inst.workdir | |
// 把子进程的 stdout/stderr 都写到 wpipe,由前面的 rpipe/merger 统一读取 | |
cmd.Stdout = wpipe | |
cmd.Stderr = wpipe | |
// 启动 ssh 子进程 | |
if err := cmd.Start(); err != nil { | |
wpipe.Close() | |
return nil, nil, err | |
} | |
// 父进程在 Start 后关闭自己的写端,避免输出管道悬挂 | |
wpipe.Close() | |
return vmimpl.Multiplex(ctx, cmd, inst.merger, vmimpl.MultiplexConfig{ | |
Debug: inst.debug, | |
Scale: inst.timeouts.Scale, | |
}) | |
} |
# executor 回连
# server.Serve
Serve 启两个并发任务并等它们结束。一个接受并处理所有 RPC 连接;另一个在首次握手完成后做一次 “机器检查”。任一返回致命错误或上层取消上下文,整体退出.
执行时序(常见路径):
- 任务 1 开始监听并处理连接;首次连接在
handleConn内完成握手并向onHandshake发送info。 - 任务 2 收到
info后调用一次runCheck(机器 / 环境健康检查)。 - 正常运行时,任务 2 完成返回 nil,任务 1 长期阻塞在监听循环。进程退出或致命错误出现时,
ctx取消或错误上抛,g.Wait返回。
func (serv *server) Serve(ctx context.Context) error { | |
// 用带取消的 errgroup 管理两个 goroutine 的生命周期 | |
g, ctx := errgroup.WithContext(ctx) | |
// 任务 1:接受连接并处理 | |
g.Go(func() error { | |
// 底层监听循环(基于 flatrpc),每接到一条连接就回调该函数。 | |
return serv.serv.Serve(ctx, func(ctx context.Context, conn *flatrpc.Conn) error { | |
err := serv.handleConn(ctx, conn) // 每条连接的会话处理与协议逻辑 | |
if err != nil && !errors.Is(err, errFatal) { | |
log.Logf(2, "%v", err) | |
return nil | |
} | |
return err | |
}) | |
}) | |
g.Go(func() error { | |
var info *handshakeResult | |
// 任务 2:等待握手并执行机器检查 | |
select { | |
case <-ctx.Done(): // 等待上下文被取消(任务 1 失败) | |
return nil | |
case info = <-serv.onHandshake: // 一个一次性的通道,handleConn 完成首次握手后把 handshakeResult 推入。 | |
} | |
// We run the machine check specifically from the top level context, | |
// not from the per-connection one. | |
return serv.runCheck(ctx, info) | |
}) | |
// 等两个 goroutine 都结束或任何一个返回非 nil 错误 | |
return g.Wait() | |
} |
Go Tips
Go 的匿名函数(函数字面量)+ 高阶函数回调
g.Go(func() error {
// 启动 goroutine,返回 errorreturn serv.serv.Serve(ctx, func(ctx context.Context, conn *flatrpc.Conn) error {
// 这是第二层匿名函数,作为回调传给 Serveerr := serv.handleConn(ctx, conn)
if err != nil && !errors.Is(err, errFatal) {
log.Logf(2, "%v", err)
return nil
}return err})
})
第一层:
g.Go(func() error { ... })errgroup.Group.Go接受一个返回error的函数并在新 goroutine 中执行。- 相当于启动一个后台任务并把它的错误结果交给
errgroup管理。 - 当这个函数返回非 nil 错误时,
errgroup会收集并取消同组其他任务。
第二层:
serv.serv.Serve(ctx, func(ctx, conn) error { ... })serv.serv.Serve是一个服务器主循环函数,它接受一个回调函数。
每当有新连接建立时,它就调用这个回调。- 回调类型是
func(context.Context, *flatrpc.Conn) error。 - 在这里,匿名函数体内调用
serv.handleConn来处理每条连接。 - 若返回的错误不是致命错误(
errFatal以外),仅记录日志并返回nil,表示这条连接处理完毕但不影响主循环。
Go 的多路通信选择语句
select {
case <-ctx.Done():
return nil // 上下文取消
case msg := <-ch:
handle(msg) // 收到消息
}- 同时监听多个 channel 或
context.Done()。 - 谁先 “就绪”,就执行那个 case 分支。
- 若多个同时就绪,随机选一个执行。
- 同时监听多个 channel 或
Go 的从通道中取值
case info = <-serv.onHandshake表示从通道取值。取出的值赋给变量
info。如果通道暂时没值,该 case 阻塞,直到:
- 通道里有数据;
- 或 select 里其他 case 先触发。
# 连接检查
# server.runCheck
runCheck 执行一次 “机器检查”(machine check)。它基于握手信息检测目标机可用的系统调用与功能特性,并把结果提交给 manager,更新后续任务的输入源。失败时返回错误;被中止则静默结束。
func (serv *server) runCheck(ctx context.Context, info *handshakeResult) error { | |
// 向外部发出 “检查已开始” 的一次性通知。 | |
if serv.cfg.machineCheckStarted != nil { | |
close(serv.cfg.machineCheckStarted) | |
} | |
// 输入:镜像 / 内核相关文件 info.Files 与初始特性 info.Features。 | |
// 输出:启用的 syscalls、禁用的 syscalls、探测到的特性 features。 | |
enabledCalls, disabledCalls, features, checkErr := serv.checker.Run(ctx, info.Files, info.Features) | |
if checkErr == vminfo.ErrAborted { | |
return nil | |
} | |
// 基于目标平台的依赖关系,移除因依赖缺失而 “间接不可用” 的调用;记录这些 “传递性禁用”。 | |
enabledCalls, transitivelyDisabled := serv.target.TransitivelyEnabledCalls(enabledCalls) | |
// Note: need to print disbled syscalls before failing due to an error. | |
// This helps to debug "all system calls are disabled". | |
if serv.cfg.PrintMachineCheck { | |
serv.printMachineCheck(info.Files, enabledCalls, disabledCalls, transitivelyDisabled, features) | |
} | |
if checkErr != nil { | |
return checkErr | |
} | |
enabledFeatures := features.Enabled() // 最终启用的特性集合。 | |
serv.setupFeatures = features.NeedSetup() // 后续需要额外初始化的特性标记,供运行阶段使用 | |
// 把 “可用特性 + 可用 syscalls” 交给 manager,让其基于此生成新的任务 / 程序来源 newSource | |
// (例如过滤掉不可用调用的变异源)。 | |
newSource, err := serv.mgr.MachineChecked(enabledFeatures, enabledCalls) | |
if err != nil { | |
return err | |
} | |
serv.baseSource.Store(newSource) // 原子更新 baseSource,后续连接将使用新源 | |
serv.checkDone.Store(true) // 标记检查完成 | |
return nil | |
} |
# Manager.MachineChecked
MachineChecked 接收 “机器检查” 结果,把 “可用调用 + 特性” 固化到 Manager,切换到下一阶段,并按运行模式构建任务源 queue.Source 给调度器使用。本函数返回的 queue.Source 被 serv.runCheck 存入 serv.baseSource 。调度器在 Loop 中从 Source 拉取 queue.Request ,生成给各 VM 的执行任务。若 Snapshot 分支,默认任务被替换,RPC 关闭,后续走快照分发路径。
func (mgr *Manager) MachineChecked(features flatrpc.Feature, | |
enabledSyscalls map[*prog.Syscall]bool) (queue.Source, error) { | |
if len(enabledSyscalls) == 0 { | |
return nil, fmt.Errorf("all system calls are disabled") | |
} | |
if mgr.mode.ExitAfterMachineCheck { | |
mgr.exit(mgr.mode.Name) | |
} | |
mgr.mu.Lock() | |
defer mgr.mu.Unlock() | |
// 只允许初始化阶段进入 | |
if mgr.phase != phaseInit { | |
panic("machineChecked() called not during phaseInit") | |
} | |
if mgr.checkDone.Swap(true) { | |
panic("MachineChecked called twice") | |
} | |
mgr.enabledFeatures = features | |
// 把 enabledSyscalls 放到 HTTP 可见 | |
mgr.http.EnabledSyscalls.Store(enabledSyscalls) | |
// 记录首次连接时间 | |
mgr.firstConnect.Store(time.Now().Unix()) | |
// 统计面板计数 “启用的 syscalls 数” | |
statSyscalls := stat.New("syscalls", "Number of enabled syscalls", | |
stat.Simple, stat.NoGraph, stat.Link("/syscalls")) | |
statSyscalls.Add(len(enabledSyscalls)) | |
// 过滤并加载语料 | |
candidates := mgr.loadCorpus(enabledSyscalls) | |
// 切换阶段到 phaseLoadedCorpus | |
mgr.setPhaseLocked(phaseLoadedCorpus) | |
// 生成执行选项 | |
opts := fuzzer.DefaultExecOpts(mgr.cfg, features, *flagDebug) | |
// 几种不同的模式,返回不同的 queue.Source | |
if mgr.mode == ModeFuzzing || mgr.mode == ModeCorpusTriage { | |
// 建立聚焦语料库 | |
corpusUpdates := make(chan corpus.NewItemEvent, 128) | |
mgr.corpus = corpus.NewFocusedCorpus(context.Background(), | |
corpusUpdates, mgr.coverFilters.Areas) | |
mgr.http.Corpus.Store(mgr.corpus) // 放入 http | |
// 新建 fuzzer 对象 | |
rnd := rand.New(rand.NewSource(time.Now().UnixNano())) | |
// 配置项:是否 snapshot,是否采集覆盖,是否 FaultInjection/Comparisons, | |
// 是否允许碰撞,是否启用调用集,禁止变异的调用集,是否抓原始覆盖。 | |
fuzzerObj := fuzzer.NewFuzzer(context.Background(), &fuzzer.Config{ | |
Corpus: mgr.corpus, | |
Snapshot: mgr.cfg.Snapshot, | |
Coverage: mgr.cfg.Cover, | |
FaultInjection: features&flatrpc.FeatureFault != 0, | |
Comparisons: features&flatrpc.FeatureComparisons != 0, | |
Collide: true, | |
EnabledCalls: enabledSyscalls, | |
NoMutateCalls: mgr.cfg.NoMutateCalls, | |
FetchRawCover: mgr.cfg.RawCover, | |
Logf: func(level int, msg string, args ...interface{}) { | |
if level != 0 { | |
return | |
} | |
log.Logf(level, msg, args...) | |
}, | |
NewInputFilter: func(call string) bool { | |
mgr.mu.Lock() | |
defer mgr.mu.Unlock() | |
return !mgr.saturatedCalls[call] | |
}, | |
}, rnd, mgr.target) | |
fuzzerObj.AddCandidates(candidates) // 预热语料 | |
mgr.fuzzer.Store(fuzzerObj) // 把 fuzzerObj 存到 mgr.fuzzer 和 HTTP | |
mgr.http.Fuzzer.Store(fuzzerObj) | |
// 起后台协程: | |
go mgr.corpusInputHandler(corpusUpdates) // 消费新样本 | |
go mgr.corpusMinimization() // 做最小化 | |
go mgr.fuzzerLoop(fuzzerObj) // 负责变异与派样 | |
if mgr.dash != nil { | |
go mgr.dashboardReporter() | |
if mgr.cfg.Reproduce { | |
go mgr.dashboardReproTasks() | |
} | |
} | |
source := queue.DefaultOpts(fuzzerObj, opts) // 构建默认任务源 | |
// 若 Snapshot 模式 | |
if mgr.cfg.Snapshot { | |
log.Logf(0, "restarting VMs for snapshot mode") | |
mgr.snapshotSource = queue.Distribute(source) | |
mgr.pool.SetDefault(mgr.snapshotInstance) // 把调度器默认任务切成 mgr.snapshotInstance | |
mgr.serv.Close() // 关闭当前 RPC server | |
mgr.serv = nil | |
return queue.Callback(func() *queue.Request { // 返回一个空回调源 | |
return nil | |
}), nil | |
} | |
return source, nil // 非 snapshot 模式直接返回 source | |
} else if mgr.mode == ModeCorpusRun { | |
ctx := &corpusRunner{ // 构造只跑语料的上下文 | |
candidates: candidates, | |
rnd: rand.New(rand.NewSource(time.Now().UnixNano())), | |
} | |
return queue.DefaultOpts(ctx, opts), nil | |
} else if mgr.mode == ModeRunTests { | |
// 指定 sys/<OS>/test 目录、Target、特性、启用调用映射(按 sandbox)。 | |
//verbose 和 debug 选项。 | |
ctx := &runtest.Context{ | |
Dir: filepath.Join(mgr.cfg.Syzkaller, "sys", mgr.cfg.Target.OS, "test"), | |
Target: mgr.cfg.Target, | |
Features: features, | |
EnabledCalls: map[string]map[*prog.Syscall]bool{ | |
mgr.cfg.Sandbox: enabledSyscalls, | |
}, | |
LogFunc: func(text string) { fmt.Println(text) }, | |
Verbose: true, | |
Debug: *flagDebug, | |
Tests: *flagTests, | |
} | |
ctx.Init() | |
// 起协程跑 ctx.Run | |
go func() { | |
err := ctx.Run(context.Background()) | |
if err != nil { | |
log.Fatal(err) | |
} | |
mgr.exit("tests") | |
}() | |
return ctx, nil | |
} else if mgr.mode == ModeIfaceProbe { | |
// 简单队列 | |
exec := queue.Plain() | |
// 起协程跑 ifaceprobe.Run (...),将结果写 interfaces.json,完成后退出 | |
go func() { | |
res, err := ifaceprobe.Run(vm.ShutdownCtx(), mgr.cfg, features, exec) | |
if err != nil { | |
log.Fatalf("interface probing failed: %v", err) | |
} | |
path := filepath.Join(mgr.cfg.Workdir, "interfaces.json") | |
if err := osutil.WriteJSON(path, res); err != nil { | |
log.Fatal(err) | |
} | |
mgr.exit("interface probe") | |
}() | |
return exec, nil | |
} | |
panic(fmt.Sprintf("unexpected mode %q", mgr.mode.Name)) | |
} |
# 处理连接并建立 fuzz
# Serv.Serve
Serv.Serve 是一个并发 TCP RPC 服务端循环,他接受所有传入的连接,并对每一个连接调用处理函数。若任一连接报错,会关闭所有连接并中止整个服务。
// Serve accepts incoming connections and calls handler for each of them. | |
// An error returned from the handler stops the server and aborts the whole processing. | |
//baseCtx 控制整体生命周期 | |
//handler 连接的处理函数 | |
func (s *Serv) Serve(baseCtx context.Context, handler func(context.Context, *Conn) error) error { | |
eg, ctx := errgroup.WithContext(baseCtx) | |
go func() { | |
// 只要 ctx 被取消(外部取消或有子任务返回错误),就关闭该服务。 | |
<-ctx.Done() | |
s.Close() | |
}() | |
for { | |
conn, err := s.ln.Accept() | |
// 若监听器已关闭并返回 net.ErrClosed,跳出循环,转入 eg.Wait () 等待现有连接结束。 | |
if err != nil && errors.Is(err, net.ErrClosed) { | |
break | |
} | |
if err != nil { | |
// 其他错误,判断是否是临时的 | |
var netErr *net.OpError | |
// 返回致命错误并终止服务 | |
if errors.As(err, &netErr) && !netErr.Temporary() { | |
return fmt.Errorf("flatrpc: failed to accept: %w", err) | |
} | |
// 打印日志后 continue,保持服务 | |
log.Logf(0, "flatrpc: failed to accept: %v", err) | |
continue | |
} | |
// 为每个 Accept 到的连接启动一个 errgroup 子协程 | |
eg.Go(func() error { | |
// 为该连接派生子上下文 connCtx。当上层 ctx 被取消时,connCtx 也会取消 | |
connCtx, cancel := context.WithCancel(ctx) | |
defer cancel() | |
c := NewConn(conn) | |
// Closing the server does not automatically close all the connections. | |
//connCtx.Done () 时关闭该连接,促使 handler 尽快返回 | |
go func() { | |
<-connCtx.Done() // 不关心 channel 中的数据,只是阻塞等待 connCtx 关闭,在该 channel 关闭后继续执行下文 | |
c.Close() | |
}() | |
//handler 的返回错误会被 errgroup 收集,并触发 ctx 取消,进而关闭监听器和所有连接。 | |
return handler(connCtx, c) | |
}) | |
} | |
return eg.Wait() | |
} |
这里的 handler 函数就是 Serv.Serve 中实现的匿名函数,最终会去调用 server.handleConn 。
# server.handleConn
handleConn 处理一条来自执行器(runner)的 RPC 连接:完成握手鉴权,绑定到已登记的 runner,交给会话处理;异常通过通道回传给调度侧,而非向上抛。
func (serv *server) handleConn(ctx context.Context, conn *flatrpc.Conn) error { | |
// 使用随机 cookie,避免 fuzzer 猜到并对多个 manager 发起 DDoS 攻击。 | |
helloCookie := rand.Uint64() | |
// 期望 Cookie | |
expectCookie := authHash(helloCookie) | |
// 发送 Hello 消息 | |
connectHello := &flatrpc.ConnectHello{ | |
Cookie: helloCookie, | |
} | |
if err := flatrpc.Send(conn, connectHello); err != nil { | |
// The other side is not an executor. | |
return fmt.Errorf("failed to establish connection with a remote runner") | |
} | |
// 接收响应 | |
connectReq, err := flatrpc.Recv[*flatrpc.ConnectRequestRaw](conn) | |
if err != nil { | |
return err | |
} | |
id := int(connectReq.Id) | |
// 验证 Cookie | |
// 这里的 Cookie 是对方收到 Hello 后计算 authHash 并发回的。 | |
// 这样可以防止伪造源 IP 的攻击(因为对方必须能收到 Hello 并计算出正确的 Cookie)。 | |
// 但无法防止中间人攻击(MITM),因为中间人也能收到 Hello 并计算出正确的 Cookie。 | |
if connectReq.Cookie != expectCookie { | |
return fmt.Errorf("client failed to respond with a valid cookie: %v (expected %v)", connectReq.Cookie, expectCookie) | |
} | |
// From now on, assume that the client is well-behaving. | |
log.Logf(1, "runner %v connected", id) | |
if serv.cfg.VMLess { | |
// 没有 VM 调度环,模拟 VM 生命周期 | |
serv.CreateInstance(id, nil, nil) | |
defer func() { | |
serv.StopFuzzing(id) | |
serv.ShutdownInstance(id, true) | |
}() | |
} else if err := checkRevisions(connectReq, serv.cfg.Target); err != nil { // 否则校验版本匹配 | |
return err | |
} | |
serv.StatVMRestarts.Add(1) // 统计一次 VM 重连 / 重启 | |
serv.mu.Lock() | |
runner := serv.runners[id] // 查找对应 ID 的 runner | |
serv.mu.Unlock() | |
if runner == nil { | |
return fmt.Errorf("unknown VM %v tries to connect", id) | |
} | |
// 执行会话协议(收发任务、覆盖、报告等) | |
err = serv.handleRunnerConn(ctx, runner, conn) | |
log.Logf(2, "runner %v: %v", id, err) | |
// 记录结果日志,runner.resultCh <- err 把本次连接结果送回 runner 协程,由其决定重启或退出 | |
runner.resultCh <- err | |
return nil | |
} |
# server.handleRunnerConn
handleRunnerConn 为新连接的 runner 完成握手配置、触发一次性 “机器检查” 通知、按需要下发 “语料已分拣完成” 标志,然后进入主会话循环。
func (serv *server) handleRunnerConn(ctx context.Context, runner *Runner, conn *flatrpc.Conn) error { | |
// 组装握手参数 handshakeConfig | |
opts := &handshakeConfig{ | |
VMLess: serv.cfg.VMLess, // 是否无 VM 模式 | |
Files: serv.checker.RequiredFiles(), // 检查阶段需要的文件列表 | |
Timeouts: serv.timeouts, // 超时设置 | |
Callback: serv.handleMachineInfo, // 握手中收集到的机器信息回调给服务端 | |
} | |
// 用于过滤已知泄漏 / 数据竞争栈帧 | |
opts.LeakFrames, opts.RaceFrames = serv.mgr.BugFrames() | |
// 若 checkDone 为真,用 setupFeatures(机检得出的最终特性,需要额外初始化)。 | |
// 否则用配置中的初始特性 cfg.Features 先启动机检。 | |
if serv.checkDone.Load() { | |
opts.Features = serv.setupFeatures | |
} else { | |
opts.Files = append(opts.Files, serv.checker.CheckFiles()...) | |
opts.Features = serv.cfg.Features | |
} | |
// 握手,交换信息,探测可用 syscalls、特性、内核文件等 | |
info, err := runner.Handshake(conn, opts) | |
if err != nil { | |
log.Logf(1, "%v", err) | |
return err | |
} | |
select { | |
// 首次握手把 info 投给 onHandshake,由 Serve 的另一路协程调用 runCheck。 | |
// 使用 default 防阻塞,若已投递过一次则跳过 | |
case serv.onHandshake <- &info: | |
default: | |
} | |
// 若语料已分拣完成,提醒 runner | |
if serv.triagedCorpus.Load() { | |
if err := runner.SendCorpusTriaged(); err != nil { | |
return err | |
} | |
} | |
// 进入主循环:领取任务、执行程序、上传覆盖、上报崩溃、心跳等。 | |
return serv.connectionLoop(ctx, runner) | |
} |
# server.connectionLoop
connectionLoop 为单个 runner 建立会话生命周期与初始状态,然后把控制权交给 runner.ConnectionLoop() 。
func (serv *server) connectionLoop(baseCtx context.Context, runner *Runner) error { | |
// To "cancel" the runner's loop we need to call runner.Stop(). | |
// At the same time, we don't want to leak the goroutine that monitors it, | |
// so we derive a new context and cancel it on function exit. | |
// 创建子上下文 ctx,函数退出时 cancel ()。 | |
ctx, cancel := context.WithCancel(baseCtx) | |
defer cancel() | |
// 起协程监听 ctx.Done (),触发 runner.Stop ()。 | |
go func() { | |
<-ctx.Done() | |
runner.Stop() | |
}() | |
if serv.cfg.Cover { | |
// 取当前全局最大信号 | |
maxSignal := serv.mgr.MaxSignal().ToRaw() | |
for len(maxSignal) != 0 { | |
// Split coverage into batches to not grow the connection serialization | |
// buffer too much (we don't want to grow it larger than what will be needed | |
// to send programs). | |
// 分批每次最多 50,000 条调用 runner.SendSignalUpdate (...) 下发,避免序列化缓冲过大。 | |
n := min(len(maxSignal), 50000) | |
if err := runner.SendSignalUpdate(maxSignal[:n]); err != nil { | |
return err | |
} | |
maxSignal = maxSignal[n:] | |
// 这是 “先给 runner 基线覆盖集”,让它去重和增量报告 | |
} | |
} | |
serv.StatNumFuzzing.Add(1) // 活跃 fuzzing runner +1 | |
defer serv.StatNumFuzzing.Add(-1) // 退出时 -1 | |
// 进入 runner 的连接循环 | |
return runner.ConnectionLoop() | |
} |
# fuzzer 包装
「fuzzer」在 syzkaller 中是一个独立的核心模块,对应于 Fuzzer 类,专门负责:
- 语料管理
- 变异策略 / 调用概率分布(choice table)
- 覆盖率收集与去重
- 执行任务(通过 exec source 输出 Request)
- 筛选新覆盖样本并加入 corpus
- 内部统计与自适应策略
包装关系图:
Fuzzer (实现 Source) | |
↓ 产出 Request | |
DefaultOpts(Source, opts) ← 加默认执行设置 | |
↓ | |
Retry(Source) ← 失败时重试 | |
↓ | |
Distribute(Source) ← 根据 VM 规避策略分发 | |
↓ | |
Runner.ConnectionLoop ← 最终执行 |
# NewFuzzer
Fuzzer 类的定义和构造函数如下:
type Fuzzer struct { | |
Stats // 运行统计与计数 | |
Config *Config //fuzzer 行为配置(覆盖、fault、过滤器等) | |
Cover *Cover // 本地覆盖数据聚合器。 | |
ctx context.Context // 生命周期与取消 | |
mu sync.Mutex // 保护内部可变状态 | |
rnd *rand.Rand // 全局随机源 | |
target *prog.Target // 系统调用与类型模型 | |
hintsLimiter prog.HintsLimiter // 比较提示的节流器 | |
runningJobs map[jobIntrospector]struct{} // 当前活跃任务集合,做并发与可见性控制 | |
ct *prog.ChoiceTable // 生成与变异时的 ChoiceTable | |
ctProgs int // 用于判断何时再生 ChoiceTable 的计数器 | |
ctMu sync.Mutex // 保护 ct 读写 | |
ctRegenerate chan struct{} // 无缓冲信号通道,触发重建 ChoiceTable;并发多次触发时只保留一次,避免频繁重建。 | |
execQueues // 多队列调度器, 将不同来源的程序(候选、变异、回放、复现)统一排队,供上游 queue.Source 拉取 | |
} | |
func NewFuzzer(ctx context.Context, cfg *Config, rnd *rand.Rand, | |
target *prog.Target) *Fuzzer { | |
// 设为恒真函数。避免空指针,允许后续按调用名做饱和过滤。 | |
if cfg.NewInputFilter == nil { | |
cfg.NewInputFilter = func(call string) bool { | |
return true | |
} | |
} | |
// 构造实例 | |
f := &Fuzzer{ | |
Stats: newStats(target), | |
Config: cfg, | |
Cover: newCover(), | |
ctx: ctx, | |
rnd: rnd, | |
target: target, | |
runningJobs: map[jobIntrospector]struct{}{}, | |
// We're okay to lose some of the messages -- if we are already | |
// regenerating the table, we don't want to repeat it right away. | |
ctRegenerate: make(chan struct{}), | |
} | |
f.execQueues = newExecQueues(f) // 准备各类执行请求的出入口 | |
f.updateChoiceTable(nil) // 生成首版 ChoiceTable(基于目标与当前语料 / 启用调用集) | |
go f.choiceTableUpdater() // 监听 ctRegenerate 与阈值,按需重建 ChoiceTable,平滑自适应权重。 | |
if cfg.Debug { | |
go f.logCurrentStats() // 定期输出统计快照 | |
} | |
return f | |
} |
Go 匿名字段
Go 支持在创建结构体时,字段只有类型,没有字段名。这样的字段称为匿名字段(Anonymous Field),也称为嵌入字段。结构体、自定义类型、内置类型都可以作为匿名字段,也可以进行相应的函数操作。当 struct A 被嵌入到 struct B 中后, struct B 就包含了 struct A 的所有字段。 Fuzzer 中的 States 和 execQueues 都是匿名字段。
executor 具体执行的 prog 及调度是由 fuzzer 来控制的,其在 Manager.MachineChecked 中由 fuzzer.NewFuzzer 来创建,关键代码为:
// 新建 fuzzer 对象 | |
rnd := rand.New(rand.NewSource(time.Now().UnixNano())) | |
// 配置项:是否 snapshot,是否采集覆盖,是否 FaultInjection/Comparisons, | |
// 是否允许碰撞,是否启用调用集,禁止变异的调用集,是否抓原始覆盖。 | |
fuzzerObj := fuzzer.NewFuzzer(context.Background(), &fuzzer.Config{ | |
Corpus: mgr.corpus, | |
Snapshot: mgr.cfg.Snapshot, | |
Coverage: mgr.cfg.Cover, | |
FaultInjection: features&flatrpc.FeatureFault != 0, | |
Comparisons: features&flatrpc.FeatureComparisons != 0, | |
Collide: true, | |
EnabledCalls: enabledSyscalls, | |
NoMutateCalls: mgr.cfg.NoMutateCalls, | |
FetchRawCover: mgr.cfg.RawCover, | |
Logf: func(level int, msg string, args ...interface{}) { | |
if level != 0 { | |
return | |
} | |
log.Logf(level, msg, args...) | |
}, | |
NewInputFilter: func(call string) bool { | |
mgr.mu.Lock() | |
defer mgr.mu.Unlock() | |
return !mgr.saturatedCalls[call] | |
}, | |
}, rnd, mgr.target) | |
fuzzerObj.AddCandidates(candidates) // 预热语料 | |
mgr.fuzzer.Store(fuzzerObj) // 把 fuzzerObj 存到 mgr.fuzzer 和 HTTP | |
mgr.http.Fuzzer.Store(fuzzerObj) | |
// 起后台协程: | |
go mgr.corpusInputHandler(corpusUpdates) // 消费新样本 | |
go mgr.corpusMinimization() // 做最小化 | |
go mgr.fuzzerLoop(fuzzerObj) // 负责变异与派样 | |
if mgr.dash != nil { | |
go mgr.dashboardReporter() | |
if mgr.cfg.Reproduce { | |
go mgr.dashboardReproTasks() | |
} | |
} | |
source := queue.DefaultOpts(fuzzerObj, opts) // 构建默认任务源 |
# queue.DefaultOpts
在构建最终任务源时( MachineChecked 内),manager 会:
opts := fuzzer.DefaultExecOpts(...) | |
source := queue.DefaultOpts(fuzzerObj, opts) |
即 “把默认执行配置加入所有请求”。这里的 DefaultOpts 是一个简单的装饰器,用来把统一的 ExecOpts (执行选项)应用到所有从某个 Source 产出的请求( Request )上。在 syzkaller 的不同模式中,执行器需要传入各种配置,例如:是否启用覆盖收集、是否启用比较指令、是否启用故障注入、使用何种沙箱、但 Request 本身只是一个 “程序 + 优先级 + 其他信息”,所以默认执行选项统一加在最外层对所有请求生效。代码如下:
// DefaultOpts applies opts to all requests in source. | |
func DefaultOpts(source Source, opts flatrpc.ExecOpts) Source { | |
return &defaultOpts{source, opts} | |
} | |
type defaultOpts struct { | |
source Source // 原始 source | |
opts flatrpc.ExecOpts // 默认执行选项 opts | |
} | |
func (do *defaultOpts) Next() *Request { | |
// 从底层 source.Next () 取一个请求 | |
req := do.source.Next() | |
if req == nil { | |
return nil | |
} | |
// 将默认选项 “叠加” 到该请求上 | |
req.ExecOpts.ExecFlags |= do.opts.ExecFlags // 执行标志按位或,保留原设置再附加默认设置 | |
req.ExecOpts.EnvFlags |= do.opts.EnvFlags // 附加默认环境标志 | |
req.ExecOpts.SandboxArg = do.opts.SandboxArg // 替换沙箱参数 | |
return req | |
} |
# queue.Retry
queue.Retry 是一个给任务源 Source 加 “自动重试” 能力的包装器。对 “VM 重启” 和 “崩溃导致的中断” 做有限重试,其他结果不重试。
type retryer struct { | |
pq *PlainQueue | |
base Source | |
} | |
// Retry adds a layer that resends results with Status=Restarted. | |
func Retry(base Source) Source { | |
return &retryer{ | |
base: base, | |
pq: Plain(), // 本地简单队列,用来暂存待重试请求 | |
} | |
} | |
func (r *retryer) Next() *Request { | |
// 先从本地 pq.tryNext () 取重试请求 | |
req := r.pq.tryNext() | |
if req == nil { | |
// 若无,则从底层 base.Next () 取新请求 | |
req = r.base.Next() | |
} | |
if req != nil { | |
// 若取到请求,注册完成回调 req.OnDone (r.done) | |
req.OnDone(r.done) | |
} | |
return req | |
} | |
// 返回 true 表示这次请求生命周期结束; | |
//false 表示要重试,且回调里已把请求塞回 pq | |
func (r *retryer) done(req *Request, res *Result) bool { | |
switch res.Status { | |
case Success, ExecFailure, Hanged: // 成功或执行失败 / 卡死不重试 | |
return true | |
case Restarted: // VM 重启导致的丢失,重试一次 | |
// The input was on a restarted VM. | |
r.pq.Submit(req) | |
return false | |
case Crashed: // VM 崩溃导致的丢失的请求,必须为重要请求且未因崩溃重试过,可重试一次 | |
if req.Important && !req.onceCrashed { | |
req.onceCrashed = true | |
r.pq.Submit(req) | |
return false | |
} | |
return true | |
default: | |
panic(fmt.Sprintf("unhandled status %v", res.Status)) | |
} | |
} |
# queue.Distribute
Distributor 是 “按 VM 规避规则分发请求” 的调度层。它从下游 Source 取请求,根据请求里的 Avoid 列表尽量避开指定 VM;若当前只有被避开的 VM 可用,则把请求暂存到延迟队列,等别的 VM 活跃后再发。为防饿死,超过阈值后强制下发。
type Distributor struct { | |
source Source // 底层产出请求的源(已可带重试等) | |
seq atomic.Uint64 | |
empty atomic.Bool | |
active atomic.Pointer[[]atomic.Uint64] | |
mu sync.Mutex | |
queue []*Request | |
statDelayed *stat.Val // “被延迟” 计数 | |
statUndelayed *stat.Val // “未被延迟” 计数 | |
statViolated *stat.Val // “被迫违反规避” 计数 | |
} | |
func Distribute(source Source) *Distributor { | |
return &Distributor{ | |
source: source, | |
statDelayed: stat.New("distributor delayed", "Number of test programs delayed due to VM avoidance", | |
stat.Graph("distributor")), | |
statUndelayed: stat.New("distributor undelayed", "Number of test programs undelayed for VM avoidance", | |
stat.Graph("distributor")), | |
statViolated: stat.New("distributor violated", "Number of test programs violated VM avoidance", | |
stat.Graph("distributor")), | |
} | |
} | |
// Next returns the next request to execute on the given vm. | |
func (dist *Distributor) Next(vm int) *Request { | |
dist.noteActive(vm) // 标记该 VM 最近活跃 | |
if req := dist.delayed(vm); req != nil { // 尝试从延迟队列取可以给此 VM 的请求 | |
return req | |
} | |
for { | |
// 循环从底层 source.Next () 拉新请求 | |
req := dist.source.Next() | |
// 无请求,或此请求不要求避开 vm,或虽然要避开但没有其他活跃 VM 可用,则直接返回该请求 | |
if req == nil || !contains(req.Avoid, vm) || !dist.hasOtherActive(req.Avoid) { | |
return req | |
} | |
dist.delay(req) // 入延迟队列,继续拉下一个 | |
} | |
} | |
//delay 将请求入延迟队列 | |
func (dist *Distributor) delay(req *Request) { | |
dist.mu.Lock() | |
defer dist.mu.Unlock() | |
req.delayedSince = dist.seq.Load() | |
dist.queue = append(dist.queue, req) | |
dist.statDelayed.Add(1) | |
dist.empty.Store(false) | |
} | |
//delayed 尝试从延迟队列取可以给此 VM 的请求 | |
func (dist *Distributor) delayed(vm int) *Request { | |
if dist.empty.Load() { | |
return nil | |
} | |
dist.mu.Lock() | |
defer dist.mu.Unlock() | |
seq := dist.seq.Load() | |
for i, req := range dist.queue { | |
violation := contains(req.Avoid, vm) | |
// The delayedSince check protects from a situation when we had another VM available, | |
// and delayed a request, but then the VM was taken for reproduction and does not | |
// serve requests any more. If we could not dispatch a request in 1000 attempts, | |
// we gave up and give it to any VM. | |
// 若当前 vm 在 req.Avoid 且还没 “等够”,则跳过, 1000 是个经验阈值 | |
if violation && req.delayedSince+1000 > seq { | |
continue | |
} | |
dist.statUndelayed.Add(1) | |
if violation { | |
// 若违反规避(即给了被避开的 VM),再记一次 statViolated++ | |
dist.statViolated.Add(1) | |
} | |
// 取出该请求并从 queue 删除 | |
last := len(dist.queue) - 1 | |
dist.queue[i] = dist.queue[last] | |
dist.queue[last] = nil | |
dist.queue = dist.queue[:last] | |
dist.empty.Store(len(dist.queue) == 0) | |
return req | |
} | |
return nil | |
} |
# fuzz 循环
# Runner.ConnectionLoop
Runner.ConnectionLoop 是 “单个 VM 上的执行主循环”。它把任务源里的请求持续送到执行器,接收执行结果与状态消息,并在异常或停止时退出。关键数据结构:
requests:已下发但未开始执行的队列(或映射)。executing:执行中请求集合。source:queue.Source。Next(id)产出下一个要执行的程序请求。供 fuzz、triage、回放等模式统一使用。infoc:外部订阅一次性状态的通道;runner.infoc是其提供方。
func (runner *Runner) ConnectionLoop() error { | |
// 若有 updInfo,把外部可观测状态设为 "executing"。 | |
if runner.updInfo != nil { | |
runner.updInfo(func(info *dispatcher.Info) { | |
info.Status = "executing" | |
}) | |
} | |
// 加锁检查 stopped。若已停止直接返回; | |
// 否则创建 runner.finished,用于关停路径等待该循环结束 | |
runner.mu.Lock() | |
stopped := runner.stopped | |
if !stopped { | |
runner.finished = make(chan bool) | |
} | |
runner.mu.Unlock() | |
if stopped { | |
// The instance was shut down in between, see the shutdown code. | |
return nil | |
} | |
defer close(runner.finished) | |
// 一次性信息回传通道 | |
var infoc chan []byte | |
defer func() { | |
if infoc != nil { | |
infoc <- []byte("VM has crashed") | |
} | |
}() | |
for { | |
if infoc == nil { | |
select { | |
// 首次取到 infoc := <-runner.infoc 后, | |
// 立刻发送一次 StateRequest(sendStateRequest ()),让执行器回一份状态 | |
case infoc = <-runner.infoc: | |
err := runner.sendStateRequest() | |
if err != nil { | |
return err | |
} | |
default: | |
} | |
} | |
// 保持 “在途请求数 − 正在执行数 < 2×procs”。 | |
// 即每个执行器进程预填充两个待执行请求,压低往返延迟。 | |
for len(runner.requests)-len(runner.executing) < 2*runner.procs { | |
// 拉请求 | |
req := runner.source.Next(runner.id) | |
if req == nil { | |
break | |
} | |
// 发送到执行器 | |
if err := runner.sendRequest(req); err != nil { | |
return err | |
} | |
} | |
// 当前请求为空 | |
if len(runner.requests) == 0 { | |
if !runner.Alive() { // 检查执行器是否存活 | |
return nil | |
} | |
// The runner has no new requests, so don't wait to receive anything from it. | |
// 短休眠 10ms,避免忙等 | |
time.Sleep(10 * time.Millisecond) | |
continue | |
} | |
// 接收并处理执行器消息 | |
raw, err := wrappedRecv[*flatrpc.ExecutorMessageRaw](runner) | |
if err != nil { | |
return err | |
} | |
if raw.Msg == nil || raw.Msg.Value == nil { | |
return errors.New("received no message") | |
} | |
switch msg := raw.Msg.Value.(type) { | |
// 执行器报告 “开始执行某个请求” 的事件。用于维护 executing 集合 | |
case *flatrpc.ExecutingMessage: | |
err = runner.handleExecutingMessage(msg) | |
// 一次执行完成的结果,包含覆盖、崩溃、错误等。这里会从 requests 移除并上送上层 | |
case *flatrpc.ExecResult: | |
err = runner.handleExecResult(msg) | |
// 应答上面的状态查询。将 “待处理请求列表 + 执行器自带状态 msg.Data” 拼成文本 | |
case *flatrpc.StateResult: | |
buf := new(bytes.Buffer) | |
fmt.Fprintf(buf, "pending requests on the VM:") | |
for id := range runner.requests { | |
fmt.Fprintf(buf, " %v", id) | |
} | |
fmt.Fprintf(buf, "\n\n") | |
result := append(buf.Bytes(), msg.Data...) | |
// 把结果发给观察者并清空 infoc | |
if infoc != nil { | |
infoc <- result | |
infoc = nil | |
} else { | |
// The request was solicited in detectTimeout(). | |
log.Logf(0, "status result: %s", result) | |
} | |
default: | |
return fmt.Errorf("received unknown message type %T", msg) | |
} | |
if err != nil { | |
return err | |
} | |
} | |
} |
runner.source 在 server.CreateInstance 中被赋值为 serv.execSource (参考 fuzzerInstance)。
# Runner.sendRequest
把一个 queue.Request 打包成 flatrpc 执行请求并发给执行器;分配递增的本地 id,设置标志和执行参数,必要时序列化程序或读入二进制数据;失败则就地完成该请求为失败;成功则把请求放进 runner.requests 以便结果回配。
func (runner *Runner) sendRequest(req *queue.Request) error { | |
// 本地一致性检查,失败则说明构造请求时出了编程错误,而非运行时异常 | |
if err := req.Validate(); err != nil { | |
panic(err) | |
} | |
// 为本 VM 连接分配递增请求号。用于后续结果匹配。 | |
runner.nextRequestID++ | |
id := runner.nextRequestID | |
var flags flatrpc.RequestFlag | |
if req.ReturnOutput { // 要求回传 stdout/stderr | |
flags |= flatrpc.RequestFlagReturnOutput | |
} | |
if req.ReturnError { // 要求回传错误文本 | |
flags |= flatrpc.RequestFlagReturnError | |
} | |
// 需要回传全部 signal 的调用索引 | |
allSignal := make([]int32, len(req.ReturnAllSignal)) | |
for i, call := range req.ReturnAllSignal { | |
allSignal[i] = int32(call) | |
} | |
// 拷贝执行选项 | |
opts := req.ExecOpts | |
if runner.debug { | |
opts.EnvFlags |= flatrpc.ExecEnvDebug | |
} | |
// 根据 type 准备 data | |
var data []byte | |
switch req.Type { | |
// 需要执行一个序列化程序(最常见的情况) | |
case flatrpc.RequestTypeProgram: | |
progData, err := req.Prog.SerializeForExec() | |
if err != nil { | |
// It's bad if we systematically fail to serialize programs, | |
// but so far we don't have a better handling than counting this. | |
// This error is observed a lot on the seeded syz_mount_image calls. | |
runner.stats.statExecBufferTooSmall.Add(1) | |
req.Done(&queue.Result{ | |
Status: queue.ExecFailure, | |
Err: fmt.Errorf("program serialization failed: %w", err), | |
}) | |
return nil | |
} | |
data = progData | |
// 需要执行一个原始二进制文件 | |
case flatrpc.RequestTypeBinary: | |
fileData, err := os.ReadFile(req.BinaryFile) | |
if err != nil { | |
req.Done(&queue.Result{ | |
Status: queue.ExecFailure, | |
Err: err, | |
}) | |
return nil | |
} | |
data = fileData | |
// 用于 “在 VM 内列出满足某种模式的文件名” | |
// 把 GlobPattern 以 NUL 结尾编码到 data,并强制打开 ReturnOutput(需要列匹配结果) | |
case flatrpc.RequestTypeGlob: | |
data = append([]byte(req.GlobPattern), 0) | |
flags |= flatrpc.RequestFlagReturnOutput | |
default: | |
panic("unhandled request type") | |
} | |
// 规避请求位图,用于 “同 VM 内进程规避”。 | |
var avoid uint64 | |
for _, id := range req.Avoid { | |
if id.VM == runner.id { | |
avoid |= uint64(1 << id.Proc) | |
} | |
} | |
// 包装成消息 | |
msg := &flatrpc.HostMessage{ | |
Msg: &flatrpc.HostMessages{ | |
Type: flatrpc.HostMessagesRawExecRequest, | |
Value: &flatrpc.ExecRequest{ | |
Id: id, | |
Type: req.Type, | |
Avoid: avoid, | |
Data: data, | |
Flags: flags, | |
ExecOpts: &opts, | |
AllSignal: allSignal, | |
}, | |
}, | |
} | |
// 把请求存入映射, 稍后在 handleExecResult 收到 ExecResult {Id: ...} 时 | |
// 用来取回原请求并调用 req.Done (...)。 | |
runner.requests[id] = req | |
// 通过当前连接发送消息给执行器 | |
return flatrpc.Send(runner.conn, msg) | |
} |
# Runner.handleExecResult
Runner.handleExecResult 接收执行器返回的结果,定位对应请求,整理覆盖 / 信号数据,检测执行器重启与挂起,设置结果状态并完成请求。
func (runner *Runner) handleExecResult(msg *flatrpc.ExecResult) error { | |
// 匹配请求,用 msg.Id 在 runner.requests 查找 req。 | |
req := runner.requests[msg.Id] | |
if req == nil { | |
// 找不到且该 id 在 runner.hanged:视为 “极慢返回” 的挂起结果,清理挂起标记后忽略返回 nil。 | |
if runner.hanged[msg.Id] { | |
// Got result for a program that was previously reported hanged | |
// (probably execution was just extremely slow). Can't report result | |
// to pkg/fuzzer since it already handled completion of the request, | |
// but shouldn't report an error and crash the VM as well. | |
delete(runner.hanged, msg.Id) | |
return nil | |
} | |
return fmt.Errorf("can't find executed request %v", msg.Id) | |
} | |
// 从 “已派发 / 执行中” 队列移除该请求 | |
delete(runner.requests, msg.Id) | |
delete(runner.executing, msg.Id) | |
if req.Type == flatrpc.RequestTypeProgram && msg.Info != nil { | |
// `req.Prog.Calls` 是 “原始程序”(syzkaller 生成的测试程序)中每一个系统调用; | |
// `msg.Info.Calls` 是 “执行结果信息”,包含每个 syscall 的执行结果(错误码、覆盖、信号等)。 | |
// 它们的长度应该一致 —— 因为每一个 “程序中的调用”,都会有一个 “执行结果”。 | |
for len(msg.Info.Calls) < len(req.Prog.Calls) { | |
msg.Info.Calls = append(msg.Info.Calls, &flatrpc.CallInfo{ | |
Error: 999, // 错误占位 | |
}) | |
} | |
// 裁剪到 prog 中 syscall 的数量,确保一一对应 | |
msg.Info.Calls = msg.Info.Calls[:len(req.Prog.Calls)] | |
// Freshness=0 表示本次来自新启动的 executor | |
if msg.Info.Freshness == 0 { | |
runner.stats.statExecutorRestarts.Add(1) | |
} | |
// 规范化每个调用信息(做信号 / 覆盖结构转换与校正) | |
for _, call := range msg.Info.Calls { | |
runner.convertCallInfo(call) | |
} | |
// 合并 ExtraRaw | |
if len(msg.Info.ExtraRaw) != 0 { | |
// 取第一个为基准,依次把后续的 Cover 和 Signal 直接拼接(去重留给上游做) | |
msg.Info.Extra = msg.Info.ExtraRaw[0] | |
for _, info := range msg.Info.ExtraRaw[1:] { | |
// All processing in the fuzzer later will convert signal/cover to maps and dedup, | |
// so there is little point in deduping here. | |
msg.Info.Extra.Cover = append(msg.Info.Extra.Cover, info.Cover...) | |
msg.Info.Extra.Signal = append(msg.Info.Extra.Signal, info.Signal...) | |
} | |
// 清空 ExtraRaw,并对合并后的 Extra 再 convertCallInfo | |
msg.Info.ExtraRaw = nil | |
runner.convertCallInfo(msg.Info.Extra) | |
} | |
if !runner.cover && req.ExecOpts.ExecFlags&flatrpc.ExecFlagCollectSignal != 0 { | |
// Coverage collection is disabled, but signal was requested => use a substitute signal. | |
// Note that we do it after all the processing above in order to prevent it from being | |
// filtered out. | |
// 生成替代信号,避免后续流程缺信号 | |
addFallbackSignal(req.Prog, msg.Info) | |
} | |
} | |
// 默认状态为成功 | |
status := queue.Success | |
var resErr error | |
if msg.Error != "" { | |
status = queue.ExecFailure | |
resErr = errors.New(msg.Error) | |
} else if msg.Hanged { | |
status = queue.Hanged | |
// 若是 RequestTypeProgram,记录最近一次挂起 | |
if req.Type == flatrpc.RequestTypeProgram { | |
// We only track the latest executed programs. | |
runner.lastExec.Hanged(int(msg.Id), int(msg.Proc), req.Prog.Serialize(), osutil.MonotonicNano()) | |
} | |
// 后续若继续 “迟到” 结果再特殊处理 | |
runner.hanged[msg.Id] = true | |
} | |
// 上报执行结果 | |
req.Done(&queue.Result{ | |
Executor: queue.ExecutorID{ // 执行器信息 | |
VM: runner.id, | |
Proc: int(msg.Proc), | |
}, | |
Status: status, // 上面判定的状态 | |
Info: msg.Info, // 处理后的覆盖 / 信号信息 | |
Output: slices.Clone(msg.Output), // 拷贝 msg.Output | |
Err: resErr, | |
}) | |
return nil | |
} |
# Request.Done
Request.Done 会触发在请求提交前注册的完成回调,这是 manager 处理 executor 回执的统一入口。
func (r *Request) Done(res *Result) { | |
// 执行之前注册的回调,决定请求是否真正结束 | |
if r.callback != nil { | |
//callback 是一个回调链,这里会依次执行链上的每个回调函数 | |
if !r.callback(r, res) { | |
// 直接返回,请求并未真正结束 | |
return | |
} | |
} | |
// 如果该请求绑定了统计计数器(例如记录某类请求完成次数),则加 1 | |
if r.Stat != nil { | |
r.Stat.Add(1) | |
} | |
// 确保 r.done 这个 channel 被创建出来 | |
r.initChannel() | |
// 把执行结果(覆盖、状态、错误等)存储到 r.result,等待者可以读取 | |
r.result = res | |
//r.done 是一个只关闭不写入的 channel | |
// 表示 “这个请求生命周期结束(不再执行,也不再重试)” | |
// 其他 goroutine 可以通过该 channel 安全的阻塞并获取结果。 | |
close(r.done) | |
} |
r.callback 在 Manager.MachineChecked 中被赋值为 fuzzer.genFuzz 。
# fuzz 回调
# Fuzzer.AddCandidates
把外部提供的候选程序(candidates)转换成可执行请求(queue.Request),并放入 fuzzer 的候选执行队列中,等待 runner 执行。
func (fuzzer *Fuzzer) AddCandidates(candidates []Candidate) { | |
// 记录本次加入了多少个候选程序,用于运行统计和监控。 | |
fuzzer.statCandidates.Add(len(candidates)) | |
for _, candidate := range candidates { | |
// 把每个 candidate 包装成一个 queue.Request | |
req := &queue.Request{ | |
Prog: candidate.Prog, // 测试程序 | |
ExecOpts: setFlags(flatrpc.ExecFlagCollectSignal), // 执行选项,强制设置 CollectSignal 标志 | |
Stat: fuzzer.statExecCandidate, // 已完成 request 计数器 | |
Important: true, // 标记为 “重要请求” | |
} | |
// 把请求加入 candidateQueue 并设置 flags 和优先级 | |
// 这里会自动为每个 Request 注册回调(processResult) | |
fuzzer.enqueue(fuzzer.candidateQueue, req, candidate.Flags|progCandidate, 0) | |
} | |
} |
# Fuzzer.enqueue
先 prepare 再 Submit ,确保队列中的请求已带回调。
func (fuzzer *Fuzzer) enqueue(executor queue.Executor, req *queue.Request, flags ProgFlags, attempt int) { | |
// 为请求添加回调函数 | |
fuzzer.prepare(req, flags, attempt) | |
// 线程安全地把请求追加到 FIFO 队列,必要时做切片压缩。 | |
executor.Submit(req) | |
} |
# Fuzzer.prepare
prepare 只做一件事:把 processResult 函数添加到 req 结束时的 callback 回调上。
func (fuzzer *Fuzzer) prepare(req *queue.Request, flags ProgFlags, attempt int) { | |
req.OnDone(func(req *queue.Request, res *queue.Result) bool { | |
//flags/attempt 用于 processResult 中的 triage / 最小化 / 重试策略决策。 | |
return fuzzer.processResult(req, res, flags, attempt) | |
}) | |
} |
# Request.OnDone
OnDone 接收一个 (req,res) -> bool :
- 返回
true:允许Request.Done继续收尾(统计、设置结果、close(done))。 - 返回
false:阻断收尾(常用于重试或再入队),例如retryer会在回调里把req放回重试队列。
type DoneCallback func(*Request, *Result) bool | |
func (r *Request) OnDone(cb DoneCallback) { | |
// 保存之前的回调链 | |
oldCallback := r.callback | |
// 把 r.callback 替换成一个新的包装函数(wrapper) | |
// 通过这层包装可以让 callback 函数自动递归调用回调链上的每个函数 | |
r.callback = func(req *Request, res *Result) bool { | |
// 把包装器卸掉,恢复成原来的回调链 | |
// 包装器只用来自动调用回调,不对返回结果有影响 | |
r.callback = oldCallback | |
// 调用当前注册的回调,如果它说‘不要继续’,那就停下来,整个 Done 链中断 | |
if !cb(req, res) { | |
return false | |
} | |
if oldCallback == nil { | |
return true | |
} | |
// 继续调用后面的 callback | |
return oldCallback(req, res) | |
} | |
} |
这里的 OnDone 函数实现的很巧妙,可以结合注释仔细看看是如何实现将回调函数注册成一个回调链,并自动按顺序回调的。
# Fuzzer.processResult
processResult 在一次执行结束后做三件事:决定是否做 triage、更新统计与覆盖处理、以及是否把同一程序重试入队。返回值控制 Request.Done 是否真正结束( true 结束; false 拦截以便重试 / 再入队)。
triage(分拣) ,一句话来说就是 “对一个疑似有价值的程序进行验证 + 最小化 + 判断是否加入语料库(corpus)” 。
一个 triage job 主要执行 3 步核心操作:
验证稳定性(确定覆盖 / 行为是否可靠):重新执行程序多次,每次采集 coverage /signal,如果不一致,程序不稳定 → 丢弃
最小化程序(减少长度、降低复杂度):尝试删除无关调用,尽量让程序变得最短且仍产生同样覆盖,便于存入 corpus 和后续变异
决定是否加入语料库(corpus):如果最终覆盖确实是 “新的”,则加入 corpus 并更新覆盖集合,然后通知其他 fuzzer 节点(Hub 同步),并触发后续变异 (candidates /smash)。
func (fuzzer *Fuzzer) processResult(req *queue.Request, res *queue.Result, flags ProgFlags, attempt int) bool { | |
// If we are already triaging this exact prog, this is flaky coverage. | |
// Hanged programs are harmful as they consume executor procs. | |
// 已在 triage 中的程序或这次执行挂起(Hanged)→ 不做 triage(避免重复与浪费执行器并发)。 | |
dontTriage := flags&progInTriage > 0 || res.Status == queue.Hanged | |
// Triage the program. | |
// We do it before unblocking the waiting threads because | |
// it may result it concurrent modification of req.Prog. | |
var triage map[int]*triageCall | |
if req.ExecOpts.ExecFlags&flatrpc.ExecFlagCollectSignal > 0 && res.Info != nil && !dontTriage { | |
// 针对每个 syscall 以及 “Extra” 聚合条目提取可 triage 的调用 | |
for call, info := range res.Info.Calls { | |
fuzzer.triageProgCall(req.Prog, info, call, &triage) | |
} | |
fuzzer.triageProgCall(req.Prog, res.Info.Extra, -1, &triage) | |
if len(triage) != 0 { | |
// 根据 flags 选择队列与统计信息 | |
queue, stat := fuzzer.triageQueue, fuzzer.statJobsTriage | |
if flags&progCandidate > 0 { | |
queue, stat = fuzzer.triageCandidateQueue, fuzzer.statJobsTriageCandidate | |
} | |
// 构造 triageJob:克隆程序、携带执行器 ID、要复核的调用集合 | |
job := &triageJob{ | |
p: req.Prog.Clone(), | |
executor: res.Executor, | |
flags: flags, | |
queue: queue.Append(), | |
calls: triage, | |
info: &JobInfo{ | |
Name: req.Prog.String(), | |
Type: "triage", | |
}, | |
} | |
// 记录将要 triage 的调用名列表(排序便于展示 / 去抖) | |
for id := range triage { | |
job.info.Calls = append(job.info.Calls, job.p.CallName(id)) | |
} | |
sort.Strings(job.info.Calls) | |
fuzzer.startJob(stat, job) | |
} | |
} | |
// 覆盖与耗时统计、逐调用处理 | |
if res.Info != nil { | |
fuzzer.statExecTime.Add(int(res.Info.Elapsed / 1e6)) // // ns → ms | |
// 针对每个 syscall,结合 “Extra” 处理覆盖 / 信号,驱动后续 choice table、语料更新 | |
for call, info := range res.Info.Calls { | |
fuzzer.handleCallInfo(req, info, call) | |
} | |
fuzzer.handleCallInfo(req, res.Info.Extra, -1) | |
} | |
// Corpus candidates may have flaky coverage, so we give them a second chance. | |
// 候选样本易抖动,给二 / 三次机会重试以消除随机抖动的影响 | |
maxCandidateAttempts := 3 | |
if req.Risky() { | |
// In non-snapshot mode usually we are not sure which exactly input caused the crash, | |
// so give it one more chance. In snapshot mode we know for sure, so don't retry. | |
// 崩溃后不确定触发者:非快照模式给 2 次;快照或挂起不给 | |
maxCandidateAttempts = 2 | |
if fuzzer.Config.Snapshot || res.Status == queue.Hanged { | |
maxCandidateAttempts = 0 | |
} | |
} | |
// 如果这次没有产出 triage 项,且程序来自 corpus(ProgFromCorpus),属于 “候选回放验证” 场景, | |
// 且未超过最大尝试次数,则把同一个 req 再次入 candidateQueue,attempt+1,并阻止 Done 收尾。 | |
if len(triage) == 0 && flags&ProgFromCorpus != 0 && attempt < maxCandidateAttempts { | |
// 这里需要重新入队,注册回调,因为回调链已经移除了这次触发的 processResult。 | |
fuzzer.enqueue(fuzzer.candidateQueue, req, flags, attempt+1) | |
return false // 拦截 Done,表示此请求未结束(已重新入队) | |
} | |
// 该候选请求已完成 | |
if flags&progCandidate != 0 { | |
fuzzer.statCandidates.Add(-1) | |
} | |
return true // 允许 Request.Done 正常完成 | |
} |
# Fuzzer.Submit
Fuzzer.Submit 负责并发安全的情况下向队列尾加入一个请求,并定期把还没被消费的元素往前移动,覆盖掉已经消费掉的老元素,实现 “切片原地压缩”,减少内存占用。
func (pq *PlainQueue) Submit(req *Request) { | |
// 用互斥锁保护内部切片与读指针 pos | |
pq.mu.Lock() | |
defer pq.mu.Unlock() | |
// It doesn't make sense to compact the queue too often. | |
// 惰性压缩,当消费指针 pos 超过队列长度的一半,且队列≥128 时压缩 | |
const minSizeToCompact = 128 | |
if pq.pos > len(pq.queue)/2 && len(pq.queue) >= minSizeToCompact { | |
// 把未消费段前移到切片开头,然后逐步从尾部开始删除请求,pos 递减到 0。 | |
copy(pq.queue, pq.queue[pq.pos:]) | |
for pq.pos > 0 { | |
newLen := len(pq.queue) - 1 | |
pq.queue[newLen] = nil | |
pq.queue = pq.queue[:newLen] | |
pq.pos-- | |
} | |
} | |
// 将请求追加入队列尾部,标准 FIFO | |
pq.queue = append(pq.queue, req) | |
} |
# Fuzz 变异
# newExecQueues
在整个 fuzz 过程中, Runner 不断从队列中通过 runner.source.Next() 来获取新的请求,然后将请求发送到 executor 执行,在 NewFuzzer 中通过 f.execQueues = newExecQueues(f) 将一个多源聚合的队列绑定到 fuzzer.source ,这里也是触发 prog 变异的入口。 fuzzer.source 是一个多源聚合的队列,其中包含了五个队列,五个队列按 “价值优先级” 排列并被 queue.Order(...) 轮询:triageCandidate → candidate → triage → smash → genFuzz。前面队列没有任务,才会落到后面。如果落到 genFuzz 中,就会触发变异。
// 多源合流 Source | |
type execQueues struct { | |
triageCandidateQueue *queue.DynamicOrderer // 分拣候选作业(“疑似带来新覆盖” 的候选程序,等待快速复核) | |
candidateQueue *queue.PlainQueue // 普通候选(用于 “需要跑一遍看看” 的样本) | |
triageQueue *queue.DynamicOrderer //triage/minimize 作业队列(把 “疑似有价值” 的样本做稳定性验证与最小化) | |
smashQueue *queue.PlainQueue //smash 作业(对语料做重度变异,探索更远搜索空间) | |
source queue.Source // 所有 Next 请求的来源,最终会被设置为一个 “多源调度器”,按优先级从多个队列中取请求 | |
} | |
func newExecQueues(fuzzer *Fuzzer) execQueues { | |
ret := execQueues{ | |
triageCandidateQueue: queue.DynamicOrder(), | |
candidateQueue: queue.Plain(), | |
triageQueue: queue.DynamicOrder(), | |
smashQueue: queue.Plain(), | |
} | |
// Alternate smash jobs with exec/fuzz to spread attention to the wider area. | |
skipQueue := 3 | |
if fuzzer.Config.PatchTest { | |
// When we do patch fuzzing, we do not focus on finding and persisting | |
// new coverage that much, so it's reasonable to spend more time just | |
// mutating various corpus programs. | |
skipQueue = 2 | |
} | |
// Sources are listed in the order, in which they will be polled. | |
//queue.Order 创建一个 “多源调度器”,他会按顺序轮询每个队列,找到第一个非空的队列,从中取请求并返回。 | |
// 也就是说,初始化队列的顺序就代表了其请求被处理的优先级。 | |
ret.source = queue.Order( | |
ret.triageCandidateQueue, | |
ret.candidateQueue, | |
ret.triageQueue, | |
queue.Alternate(ret.smashQueue, skipQueue), | |
queue.Callback(fuzzer.genFuzz), | |
) | |
return ret | |
} |
# Fuzzer.genFuzz
按策略 “变异优先、生成兜底”,必要时做一次 “碰撞 (collide)” 合成,然后给请求挂上 processResult 回调并返回。两种不同的变异策略:
mutate基于已有 corpus,效率高,命中率大;generate从零开始,探索性强,用于引入新结构 / 常量,防止陷入局部最优。
func (fuzzer *Fuzzer) genFuzz() *queue.Request { | |
// Either generate a new input or mutate an existing one. | |
// 默认 95% 变异现有输入,5% 走生成一个新的输入 | |
mutateRate := 0.95 | |
if !fuzzer.Config.Coverage { | |
// If we don't have real coverage signal, generate programs | |
// more frequently because fallback signal is weak. | |
// 关闭真实覆盖收集时(只有弱替代信号),把变异:生成改为 50:50,避免陷入盲目变异。 | |
mutateRate = 0.5 | |
} | |
var req *queue.Request | |
// 使用 fuzzer 自带的 RNG,保证可控的随机性与并发安全。 | |
rnd := fuzzer.rand() | |
// 先尝试变异,否则生成 | |
if rnd.Float64() < mutateRate { | |
req = mutateProgRequest(fuzzer, rnd) | |
} | |
// 可能因为 corpus 为空或筛选失败而返回 nil, | |
// 此时退回 genProgRequest 直接生成新程序。 | |
if req == nil { | |
req = genProgRequest(fuzzer, rnd) | |
} | |
// 可选 “碰撞” 合成,开启 Collide 时,以 1/3 概率把当前程序与 | |
// 另一程序 “拼接 / 交织”,制造跨调用序列的相互作用(更易触发竞态 / 复杂 bug)。 | |
if fuzzer.Config.Collide && rnd.Intn(3) == 0 { | |
req = &queue.Request{ | |
Prog: randomCollide(req.Prog, rnd), | |
Stat: fuzzer.statExecCollide, | |
} | |
} | |
// 把结果处理(triage / 最小化 / 重试)挂到请求上 | |
// 此处 flags=0, attempt=0:指这是 “即时产样” 的普通请求; | |
fuzzer.prepare(req, 0, 0) | |
return req | |
} |
# mutateProgRequest
mutateProgRequest 从已有语料库(corpus)中挑一个程序,复制一份,对它做一次随机变异,然后生成一个请求 (Request) 交给 fuzz 执行。
func mutateProgRequest(fuzzer *Fuzzer, rnd *rand.Rand) *queue.Request { | |
//corpus 是 fuzzer 已经确认有价值的程序集合。 | |
// ChooseProgram (rnd) 按一定策略(通常加权随机)挑一个程序 | |
// 如果 corpus 为空,就返回 nil,表示不能做变异,让上层退回到 genProg ()。 | |
p := fuzzer.Config.Corpus.ChooseProgram(rnd) | |
if p == nil { | |
return nil | |
} | |
//syzkaller 中程序是可变对象,不能直接修改 corpus 中的原始程序 | |
// 所以必须 clone 一份副本再变异,保证 corpus 中的数据不会被破坏 | |
newP := p.Clone() | |
// 对程序进行随机变异 | |
newP.Mutate(rnd, // 随机源 | |
prog.RecommendedCalls, // 风险较高但收益大的 “推荐系统调用” | |
fuzzer.ChoiceTable(), // 选择表,用于按概率决定调用类型、参数等 | |
fuzzer.Config.NoMutateCalls, // 不允许被变异的系统调用列表 | |
fuzzer.Config.Corpus.Programs(), // 其他程序,某些变异(如参数借用)可能会参考它们 | |
) | |
// 构造成一个请求,执行变异后的程序 | |
return &queue.Request{ | |
Prog: newP, | |
ExecOpts: setFlags(flatrpc.ExecFlagCollectSignal), | |
Stat: fuzzer.statExecFuzz, | |
} | |
} |
# genProgRequest
genProgRequest 用于从零生成一个新程序(而不是在已有 corpus 上变异),并把它封装成一个带收集信号标记的 queue.Request 返回,作为变异失败时的兜底或按概率触发以保持 prog 的多样性,从而能探索更大的空间。
func genProgRequest(fuzzer *Fuzzer, rnd *rand.Rand) *queue.Request { | |
// 调用目标平台的 Generate,用随机源 rnd 生成一个合法的 syzkaller 程序 p | |
p := fuzzer.target.Generate(rnd, | |
prog.RecommendedCalls, // 一个 prog 中推荐的 syscall 个数 | |
fuzzer.ChoiceTable()) // 选择表,基于覆盖反馈动态调整生成时各类变异的概率分布,这里提供 guided generation | |
// 包装成请求 | |
return &queue.Request{ | |
Prog: p, | |
ExecOpts: setFlags(flatrpc.ExecFlagCollectSignal), | |
Stat: fuzzer.statExecGenerate, | |
} | |
} |