# 概述
当用户空间通过 syscall 发起读 / 写命令时,如果页缓存(page cache)中没有需要的数据,就需要实际从存储介质中读取 / 写入。Linux 为了兼容各式各样的底层存储设备,抽象出了通用块设备层来作为一个统一的接口向上层(文件系统)提供高效的读 / 写服务。在 Linux 中,一次 IO 请求可以用如下简化的示意图表示。
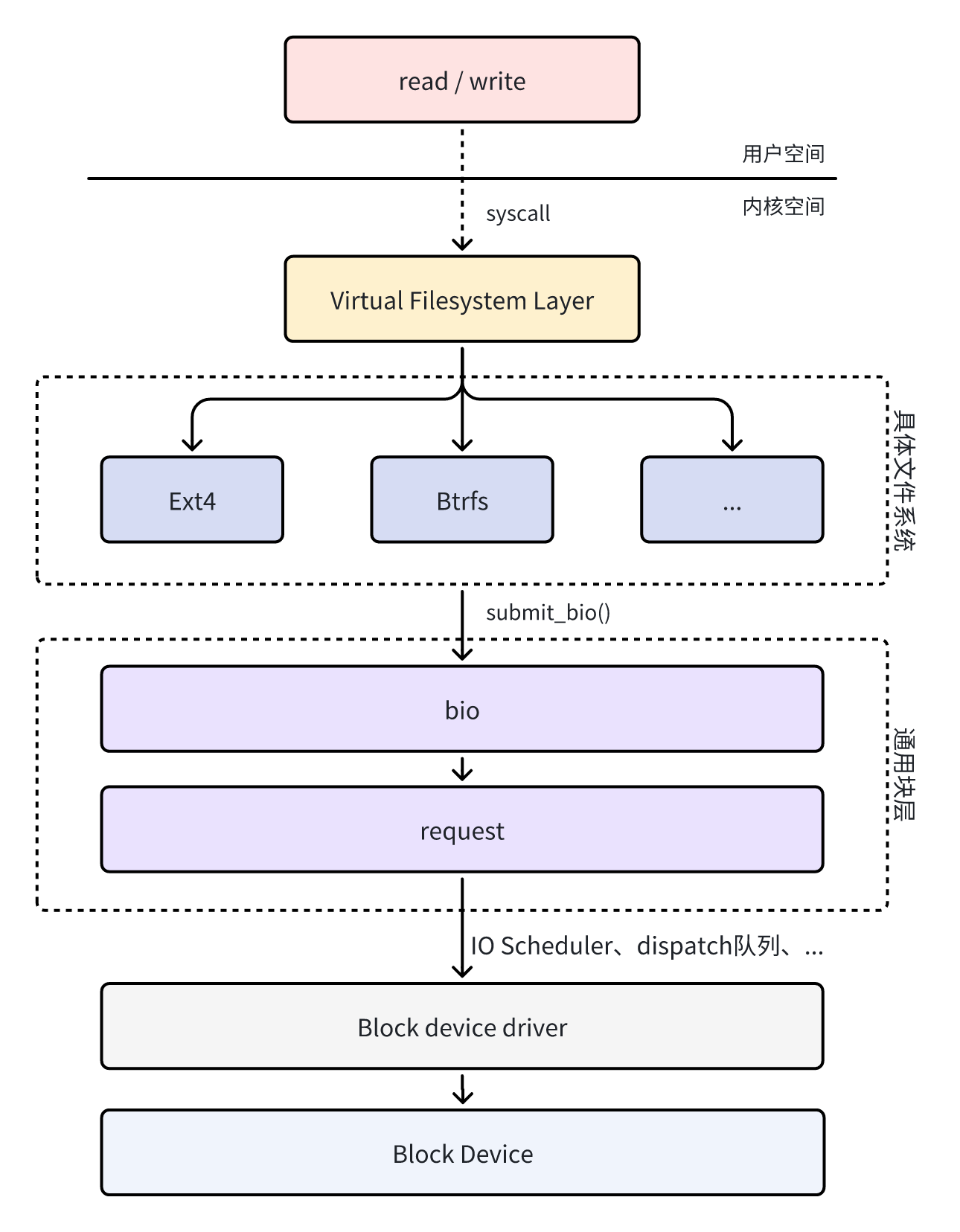
Linux 块层通过 struct bio 和 struct request 这两种抽象,把上层(如文件系统、页缓存)发起的 IO 请求,与下层(各种驱动 / 硬件)实际能够高效处理的 IO 单元进行了完美解耦和桥接,从而实现了高性能、高兼容性的通用存储框架。本篇文章主要聚焦于这两个结构:
- 上层文件系统将自己的需求包装成
struct bio,表达自己要读写位于何处的多少数据 - 块层在
struct bio的基础上进一步将 IO 请求处理成struct request结构,并下发给设备驱动处理
在实际情况中,bio 和 request 不一定是一一对应。多个 bio 可以合并到一个 request,也可能一个 bio 拆成多个 request(如跨越设备最大 IO 限制时)。块层在 submit_bio 到驱动 queue_rq 这段过程中,负责 bio→request 的组织、合并、限速和调度,极大提升了系统 IO 性能和硬件利用率。
接下来我们详细介绍一下这部分内容。
# bio 层
struct bio 是高层(文件系统 / 页缓存 / RAID/dm 等)到块层的通用 IO 请求描述,主要包括数据页(bio_vec)、IO 方向、起始扇区等,表达 “我想从这里读 / 写这些数据”。
# 关键数据结构
struct bio 的定义位于 include/linux/blk_types.h ,其字段详细含义如下:
/* | |
* main unit of I/O for the block layer and lower layers (ie drivers and | |
* stacking drivers) | |
*/ | |
struct bio { | |
struct bio *bi_next; /* 用于将多个 bio 连接成一个链表,通常用于 request queue 的合并和调度 */ | |
struct block_device *bi_bdev; /* bio 要操作的设备的指针(block_device 表示一个 “已打开的块设备 / 分区” 的实例) */ | |
blk_opf_t bi_opf; /* 用于表明这个 bio 是做什么操作的 | |
* 低 8 位代表操作类型,参考下面的 REQ_OP_* | |
* 高 24 位代表请求的 flag, 参考下面的 __REQ_* */ | |
unsigned short bi_flags; /* bio 本身的 flag,参考下面的 BIO_* */ | |
unsigned short bi_ioprio; /* IO 优先级,低层可以据此做调度优化 */ | |
blk_status_t bi_status; /* bio 的执行结果,记录 IO 操作的返回 / 完成状态 */ | |
/* | |
* 代表 bio chain 中还有几个 bio 没有处理完,默认值为 1。 | |
* 对某一个 bio 每 split 产生一个新的 bio,__bi_remaining 加 1。 | |
* chain 类型的 bio 的回调函数为 bio_chain_endio, | |
* bio_chain_endio->bio_endio->bio_remaining_done 将 __bi_remaining 减 1 | |
* 后判断 __bi_remaining 是否为 0,不为 0 说明 bio 并没有处理完(目前只是完成了 chain 中一个 bio ), | |
* bio_endio 直接返回,只有当 __bi_remaining 为 0 时,bio_endio 才会正在地执行 | |
*/ | |
atomic_t __bi_remaining; | |
struct bvec_iter bi_iter; /* 描述当前 bio 的遍历状态 | |
*(存储器端起始 sector、还剩多少个字节需要读写;) | |
*(内存端当前操作的 vector 是哪个、当前 vector 中已经完成了多少个字节) | |
*/ | |
blk_qc_t bi_cookie; | |
bio_end_io_t *bi_end_io; /* bio 完成后的回调函数指针,IO 操作完成(无论成功或失败)时调用 */ | |
void *bi_private; /* 各功能模块的私有指针,用于实现特殊功能 */ | |
/* ...(省略部分根据内核配置才启用的成员) */ | |
unsigned short bi_vcnt; /* bio 中当前 vector 数量,不能大于 bio->bi_max_vecs | |
* bio->bi_io_vec [bio->bi_vcnt] 得到的 vector 是空闲可用的 | |
*/ | |
/* | |
* 从 bi_max_vecs 成员开始的所有字段,在调用 bio_reset () 这个函数时,都会被保留,不会被重置或覆盖。 | |
*/ | |
unsigned short bi_max_vecs; /* bio 中 vector 的最大值,分配 bio 时设置 */ | |
atomic_t __bi_cnt; /* bio 的引用计数,防止 bio 被提前释放 */ | |
/* | |
* 当 bio 中的 vector 数量小于等于 BIO_INLINE_VECS(值为 4)时, | |
* bio->bi_io_vec 指向 bio 内嵌的 bio->bi_inline_vecs, | |
* 否则指向按需分配的 vector 地址。 | |
* 不管是 bio->bi_inline_vecs 还是按需分配的 vector,这些 vector 在虚拟地址上是连续的, | |
* 本质上就是一个元素为 struct bio_vec 的数组,bio->bi_io_vec 指向数组第一个元素, | |
* 将地址(bio->bi_io_vec)+ 1 即可得到下一个元素 | |
*/ | |
struct bio_vec *bi_io_vec; | |
/* | |
* 表明 bio 归属于哪个内存池(bio_set),用于 bio 释放回收。 | |
* bio 结构体在内核中会频繁的申请、释放,为了提升性能、避免内存碎片, | |
* 内核用 slab 管理 bio 内存,slab 中存放相同大小的 object(object 就是 struct bio), | |
* 这些 objcect 就构成了内存池。需要 bio 时,从内存池申请,释放时返回给内存池。 | |
*/ | |
struct bio_set *bi_pool; | |
/* | |
* bio 内嵌了 BIO_INLINE_VECS(值为 4)个 vector(struct bio_vec)。 | |
* 若 bio 需要的 vector 数量小于等于 BIO_INLINE_VECS, | |
* 可直接用这里预定义的 bi_inline_vecs, 就不需要额外申请了, | |
* 但是该字段必须位于 struct bio 的结尾处。 | |
*/ | |
struct bio_vec bi_inline_vecs[]; | |
}; |
struct bio 中的 bi_opf 字段的可选值及解释如下:
/** | |
* enum req_op - bio 和 request 结构体都通用的操作类型。 | |
* 用 8 个比特(位)来编码操作类型,剩下的 24 位用于标志位(flags)。 | |
* | |
* 操作码的最低有效位(最低一位)表示数据传输方向: | |
* | |
* - 如果最低位被置位(1),表示数据 “写入” 到设备(TO the device) | |
* - 如果最低位未被置位(0),表示数据 “读取” 自设备(FROM the device) | |
* | |
* 如果某个操作并不涉及数据传输(如 FLUSH),那么最低位没有意义。 | |
*/ | |
enum req_op { | |
/* 从设备读取扇区 */ | |
REQ_OP_READ = (__force blk_opf_t)0, | |
/* 向设备写入扇区 */ | |
REQ_OP_WRITE = (__force blk_opf_t)1, | |
/* 刷新易失性写缓存 */ | |
REQ_OP_FLUSH = (__force blk_opf_t)2, | |
/* 丢弃扇区 */ | |
REQ_OP_DISCARD = (__force blk_opf_t)3, | |
/* 安全擦除扇区(比 discard 更彻底) */ | |
REQ_OP_SECURE_ERASE = (__force blk_opf_t)5, | |
/* 向当前分区写指针写入数据 */ | |
REQ_OP_ZONE_APPEND = (__force blk_opf_t)7, | |
/* 将扇区用 0 填充多次 */ | |
REQ_OP_WRITE_ZEROES = (__force blk_opf_t)9, | |
/* 管理分区状态(打开) */ | |
REQ_OP_ZONE_OPEN = (__force blk_opf_t)10, | |
/* 管理分区状态(关闭) */ | |
REQ_OP_ZONE_CLOSE = (__force blk_opf_t)11, | |
/* 管理分区状态(已满) */ | |
REQ_OP_ZONE_FINISH = (__force blk_opf_t)12, | |
/* 重置一个分区写指针 */ | |
REQ_OP_ZONE_RESET = (__force blk_opf_t)13, | |
/* 重置设备上所有分区 */ | |
REQ_OP_ZONE_RESET_ALL = (__force blk_opf_t)15, | |
/* 驱动私有请求 */ | |
REQ_OP_DRV_IN = (__force blk_opf_t)34, | |
REQ_OP_DRV_OUT = (__force blk_opf_t)35, | |
REQ_OP_LAST = (__force blk_opf_t)36, | |
}; | |
enum req_flag_bits { | |
__REQ_FAILFAST_DEV = /* 设备层错误时不重试(fail fast,快速失败) */ | |
REQ_OP_BITS, | |
__REQ_FAILFAST_TRANSPORT, /* 传输错误不重试 */ | |
__REQ_FAILFAST_DRIVER, /* 驱动错误不重试 */ | |
__REQ_SYNC, /* 请求是同步的(如同步写 / 读) */ | |
__REQ_META, /* 元数据 IO 请求 */ | |
__REQ_PRIO, /* 提升 IO 优先级(如 CFQ 调度器下)*/ | |
__REQ_NOMERGE, /* 此请求不允许和其他请求合并 */ | |
__REQ_IDLE, /* 预期后续还有更多 IO */ | |
__REQ_INTEGRITY, /* IO 中包含数据完整性 payload */ | |
__REQ_FUA, /* 强制单元访问(Flush on Write,写完必须落盘) */ | |
__REQ_PREFLUSH, /* 请求缓存刷盘 */ | |
__REQ_RAHEAD, /* 预读(可随时失败) */ | |
__REQ_BACKGROUND, /* 后台 IO */ | |
__REQ_NOWAIT, /* 遇到阻塞直接返回,用于高并发 */ | |
__REQ_POLLED, /* 调用方使用 bio_poll 主动轮询完成 */ | |
__REQ_ALLOC_CACHE, /* 可用时从缓存分配 IO */ | |
__REQ_SWAP, /* 交换分区 IO */ | |
__REQ_DRV, /* 驱动自用标志 */ | |
__REQ_FS_PRIVATE, /* 文件系统自用标志 */ | |
/* | |
* Command specific flags, keep last: | |
*/ | |
/* for REQ_OP_WRITE_ZEROES: */ | |
__REQ_NOUNMAP, /* 全零化时不释放块 */ | |
__REQ_NR_BITS, /* 标志位数量上限 */ | |
}; |
内核中定义的 bio flags 包括如下几种:
/* | |
* bio flags | |
*/ | |
enum { | |
BIO_PAGE_PINNED, /* 在 bio_release_pages () 里需要解除页面的 “钉住” 状态。通常用于确保 bio 释放时正确释放页面引用 */ | |
BIO_CLONED, /* 该 bio 是 “克隆” 的,不拥有数据。即页面 /vector 不是它自己分配的,释放时不能主动释放数据。 */ | |
BIO_BOUNCED, /* 该 bio 是 “bounce” bio(转跳用),比如内存无法 DMA 时临时搬运用的 bio */ | |
BIO_QUIET, /* 该 bio 设置为 “静默” 模式。IO 错误等不会在日志中打印或报告 */ | |
BIO_CHAIN, /* 该 bio 是链式 bio(被链表 / 递归合并),bi_remaining 计数生效 */ | |
BIO_REFFED, /* bio 的引用计数已被提升(加过一次引用),用于防止提前释放 */ | |
BIO_BPS_THROTTLED, /* 该 bio 已经执行过 BPS(带宽)限制,不要再限速了 */ | |
BIO_TRACE_COMPLETION, /* bio_endio () 应追踪 / 记录该 bio 的最终完成。用于 trace / 调试 */ | |
BIO_CGROUP_ACCT, /* 该 bio 已经被计入了 cgroup IO 统计 */ | |
BIO_QOS_THROTTLED, /* bio 经过 rq_qos 的限速路径(request queue 的 QoS 调度) */ | |
BIO_QOS_MERGED, /* bio 经过 rq_qos 的合并路径 */ | |
BIO_REMAPPED, /* 该 bio 已被重新映射(如 device mapper 层分区 / 重定向)*/ | |
BIO_ZONE_WRITE_LOCKED, /* 拥有分区存储设备(zoned device)的 zone 写锁。确保对该 zone 的并发写入安全 */ | |
BIO_FLAG_LAST | |
}; |
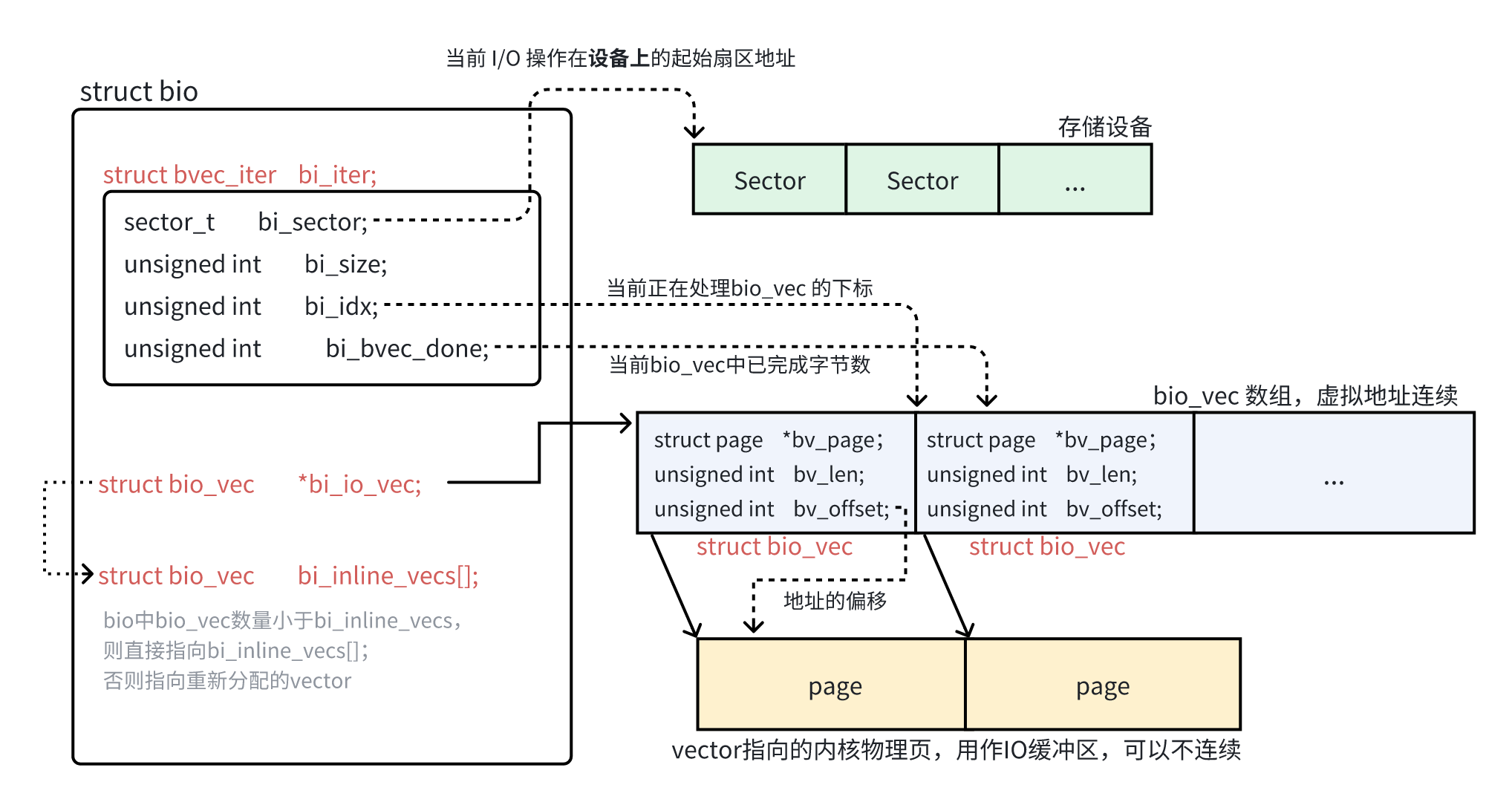
struct bio 遵循 “需求与执行” 分离的原则。 bio->bi_io_vec 描述 “需求”(即 io 会涉及到哪些 vector),其类型为 struct bio_vec ; bio->bi_iter 描述执行情况(即 bio 的处理进度,当前在处理哪个 vector、当前 vector 中已经完成了多少个字节),其类型为 struct bvec_iter 。
struct bio_vec 和 struct bvec_iter 的定义均位于 include/linux/bvec.h :
struct bvec_iter { | |
sector_t bi_sector; /* 设备扇区地址(以 512 字节为单位)。表示本次 IO 操作当前要处理的 “设备起始扇区号” */ | |
unsigned int bi_size; /* 剩余未处理的 IO 大小(字节)。表示 bio 剩余还有多少字节要处理,随着分段或分片会递减 */ | |
unsigned int bi_idx; /* 当前正在处理的 bio_vec 的下标 */ | |
unsigned int bi_bvec_done; /* 当前 bio_vec(bi_idx 指向的那个)中已完成的字节数。 */ | |
} __packed __aligned(4); |
/** | |
* struct bio_vec - 一段连续的物理内存地址区间 | |
* @bv_page: 指向与该地址区间关联的第一个内存页(struct page 指针) | |
* @bv_len: 该地址区间的总字节数 | |
* @bv_offset: 该地址区间在 @bv_page 起始处的偏移(字节为单位) | |
* | |
* 如果满足 n * PAGE_SIZE < bv_offset + bv_len(就是存在数据跨页的情况),则对一个 bvec 有: | |
* | |
* nth_page (@bv_page, n) == @bv_page + n | |
* | |
* 通常每个 bio_vec 只指向一段页内或跨页起始段,内核会通过 page_is_mergeable () 检查能否合并多个 bio_vec | |
*/ | |
struct bio_vec { | |
struct page *bv_page; | |
unsigned int bv_len; | |
unsigned int bv_offset; | |
}; |
struct bio 的主要成员关系如下:
# 执行流程
当上层模块(如文件系统)有对块设备的 IO 需求时,会封装一个 bio 结构体,并调用 submit_bio() 将该 IO 请求下发到块层处理。
# submit_bio
/** | |
* submit_bio - 向块设备层提交一个 bio 进行 I/O 操作 | |
* @bio: 用于描述本次 I/O 的 struct bio 结构体指针 | |
* | |
* submit_bio () 用于向块设备提交 I/O 请求。它接收一个已经完全设置好的 struct bio, | |
* 该 bio 描述了需要进行的 I/O 操作。bio 会被发送到其 bi_bdev 字段指定的设备上。 | |
* | |
* 本次请求的成功 / 失败状态,以及完成的通知,都会通过 bio->bi_end_io () 回调函数 | |
* 以异步方式传递,在 bi_end_io () 被调用之前,调用者【不得】修改或访问该 bio。 | |
*/ | |
void submit_bio(struct bio *bio) | |
{ | |
if (bio_op(bio) == REQ_OP_READ) { | |
task_io_account_read(bio->bi_iter.bi_size); | |
count_vm_events(PGPGIN, bio_sectors(bio)); | |
} else if (bio_op(bio) == REQ_OP_WRITE) { | |
count_vm_events(PGPGOUT, bio_sectors(bio)); | |
} | |
bio_set_ioprio(bio); | |
submit_bio_noacct(bio); | |
} | |
EXPORT_SYMBOL(submit_bio); |
# submit_bio_noacct
noacct 即 noaccounting 代表不进行统计,比如 IO 计数、内存统计、进程的 io_account、页缓存计数等,这些只需要在上层做一次即可。
/** | |
* submit_bio_noacct - 重新提交一个 bio 到块设备层进行 I/O 操作 | |
* @bio: 描述了内存和设备上的位置的 bio | |
* | |
* 这是 submit_bio () 的一个更底层的版本,仅应被 “分层块设备驱动”(stacking block drivers) | |
* 用于将 I/O 重新提交给更底层的驱动。所有文件系统以及其他块层上层用户,都应该使用 submit_bio ()。 | |
*/ | |
void submit_bio_noacct(struct bio *bio) | |
{ | |
struct block_device *bdev = bio->bi_bdev; | |
struct request_queue *q = bdev_get_queue(bdev); | |
blk_status_t status = BLK_STS_IOERR; | |
might_sleep(); | |
/* | |
* 对一个带有 REQ_NOWAIT 标志的请求,如果队列不支持 NOWIAT 则返回 -EOPNOTSUPP | |
*/ | |
if ((bio->bi_opf & REQ_NOWAIT) && !bdev_nowait(bdev)) | |
goto not_supported; | |
/* 检查一些可能会出错的场景 */ | |
if (should_fail_bio(bio)) | |
goto end_io; | |
bio_check_ro(bio); /* 检查是否是在写一个只读设备 */ | |
if (!bio_flagged(bio, BIO_REMAPPED)) { | |
if (unlikely(bio_check_eod(bio))) | |
goto end_io; | |
if (bdev->bd_partno && unlikely(blk_partition_remap(bio))) | |
goto end_io; | |
} | |
/* | |
* 及早过滤掉 flush 类型的 bio,这样不支持 flush 的基于 bio 的驱动就不必关心这些 bio 了。 | |
* op_is_flush () 用于检测 bi_opf 是否包含 REQ_PREFLUSH 或 REQ_FUA 标志,代表该 bio 要求刷写设备的易失性写缓存。 | |
*/ | |
if (op_is_flush(bio->bi_opf)) { | |
/* 如果 bio_op 既不是 REQ_OP_WRITE,也不是 REQ_OP_ZONE_APPEND,则打印警告,并提前结束 IO。 | |
* 这是因为 flush/fua 语义只适用于写入操作,对其它操作类型设置 flush 是非法用法。 | |
*/ | |
if (WARN_ON_ONCE(bio_op(bio) != REQ_OP_WRITE && | |
bio_op(bio) != REQ_OP_ZONE_APPEND)) | |
goto end_io; | |
/* 如果底层设备(队列)没有写缓存(即不需要 flush),则直接忽略 flush/fua */ | |
if (!test_bit(QUEUE_FLAG_WC, &q->queue_flags)) { | |
bio->bi_opf &= ~(REQ_PREFLUSH | REQ_FUA); | |
if (!bio_sectors(bio)) { | |
status = BLK_STS_OK; | |
goto end_io; | |
} | |
} | |
} | |
/* 如果队列没有设置 POLL 特性(即不支持轮询完成),就把 REQ_POLLED 标志清掉(即该 bio 不能用轮询方式等待完成)。 */ | |
if (!test_bit(QUEUE_FLAG_POLL, &q->queue_flags)) | |
bio_clear_polled(bio); | |
switch (bio_op(bio)) { | |
case REQ_OP_READ: | |
case REQ_OP_WRITE: | |
break; | |
case REQ_OP_FLUSH: | |
/* | |
* REQ_OP_FLUSH 不能直接通过 bio 提交,它只能由 flush 状态机在 struct request 层面合成出来 | |
*/ | |
goto not_supported; | |
case REQ_OP_DISCARD: | |
if (!bdev_max_discard_sectors(bdev)) | |
goto not_supported; | |
break; | |
case REQ_OP_SECURE_ERASE: | |
if (!bdev_max_secure_erase_sectors(bdev)) | |
goto not_supported; | |
break; | |
case REQ_OP_ZONE_APPEND: | |
status = blk_check_zone_append(q, bio); | |
if (status != BLK_STS_OK) | |
goto end_io; | |
break; | |
case REQ_OP_WRITE_ZEROES: | |
if (!q->limits.max_write_zeroes_sectors) | |
goto not_supported; | |
break; | |
case REQ_OP_ZONE_RESET: | |
case REQ_OP_ZONE_OPEN: | |
case REQ_OP_ZONE_CLOSE: | |
case REQ_OP_ZONE_FINISH: | |
if (!bdev_is_zoned(bio->bi_bdev)) | |
goto not_supported; | |
break; | |
case REQ_OP_ZONE_RESET_ALL: | |
if (!bdev_is_zoned(bio->bi_bdev) || !blk_queue_zone_resetall(q)) | |
goto not_supported; | |
break; | |
case REQ_OP_DRV_IN: | |
case REQ_OP_DRV_OUT: | |
/* 驱动私有操作(REQ_OP_DRV_IN/OUT)只允许用于直通(passthrough)请求。*/ | |
fallthrough; | |
default: | |
goto not_supported; | |
} | |
/* 如果队列有 blk-throttle 规则(限速 / 限带宽),会先在这里 “拦截”,由 blk-throtl 机制调度后再继续提交。 */ | |
if (blk_throtl_bio(bio)) | |
return; | |
/* 如果不需要限速,直接调用 submit_bio_noacct_nocheck (bio) 下发到驱动,不再进行请求类型的二次检查。 */ | |
submit_bio_noacct_nocheck(bio); | |
return; | |
not_supported: | |
status = BLK_STS_NOTSUPP; | |
end_io: | |
bio->bi_status = status; | |
bio_endio(bio); | |
} | |
EXPORT_SYMBOL(submit_bio_noacct); |
# submit_bio_noacct_nocheck
void submit_bio_noacct_nocheck(struct bio *bio) | |
{ | |
/* cgroup 的 IO 信息统计相关操作 */ | |
blk_cgroup_bio_start(bio); | |
blkcg_bio_issue_init(bio); | |
/* 检查 bio 是否已经设置了 “需要完成时追踪” 的标志(BIO_TRACE_COMPLETION)。 */ | |
if (!bio_flagged(bio, BIO_TRACE_COMPLETION)) { | |
trace_block_bio_queue(bio); | |
/* | |
* 既然已经对 bio 的入队操作进行了 trace(跟踪 / 记录),就需要对其完成(completion)也做 trace。 | |
*/ | |
bio_set_flag(bio, BIO_TRACE_COMPLETION); | |
} | |
/* | |
* 我们希望同一时刻只激活一个 ->submit_bio(块设备递交)过程, | |
* 否则在有堆叠块设备(如 device-mapper, LVM, MD)时会造成栈空间消耗问题。 | |
* 用 current->bio_list 来收集在一个 ->submit_bio 调用期间被递交的所有 bio, | |
* 等该 submit_bio 方法返回后,再统一处理这些 bio。 | |
*/ | |
if (current->bio_list) // 当前进程的 bio_list 已经存在,即处于一个递归 / 嵌套的 submit_bio 调用过程中 | |
bio_list_add(¤t->bio_list[0], bio); // 先把 bio 添加到 current->bio_list 中,不马上递交 | |
else if (!bio->bi_bdev->bd_has_submit_bio) // 如果目标 block_device 没有实现 bd_has_submit_bio (即没有自定义递交函数) | |
__submit_bio_noacct_mq(bio); // 调用基于 MQ(多队列块层)的递交函数 | |
else | |
__submit_bio_noacct(bio); // 调用设备专用的 submit_bio 递交函数 | |
} |
# __submit_bio_noacct
块设备提交 I/O(bio)过程中, submit_bio() 可能导致递归调用自身,递归过程中可能又生成新的 bio(例如多层设备映射、加密、压缩、RAID 等),为避免递归导致栈爆炸,Linux 块层设计了两级 bio_list 机制
递归部分需要结合着 submit_bio_noacct_nocheck 一起来看。
/* | |
* 这个函数中的循环可能有些不太直观,因此需要做一些解释: | |
* | |
* - 在进入循环之前,bio->bi_next 是 NULL(调用者都会确保这一点), | |
* 所以我们最开始的 bio 链表中只有一个 bio。 | |
* | |
* - 我们假装它是从一个更长的链表中取出来的,因此我们将 bio_list 指向 | |
* bio_list_on_stack,从而初始化用于添加新 bio 的 bio_list。 | |
* ->submit_bio () 的确可能会通过递归调用 submit_bio_noacct 添加更多的 bio。 | |
* 如果确实添加了新的 bio,我们会在 bio_list 中发现非 NULL 的值, | |
* 然后从循环顶端重新进入。 | |
* | |
* - 这个时候我们是真的从 bio_list 的顶部取出一个 bio(不再是假装), | |
* 所以我们从 bio_list 中移除该 bio,并再次调用 ->submit_bio () 处理它。 | |
* | |
* bio_list_on_stack [0] 保存的是当前这次 ->submit_bio 提交过程中生成的 bio。 | |
* bio_list_on_stack [1] 保存的是在当前这次 ->submit_bio 之前提交、但尚未处理的 bio。 | |
*/ | |
static void __submit_bio_noacct(struct bio *bio) | |
{ | |
struct bio_list bio_list_on_stack[2]; | |
/* bio->bi_next 应为 NULL,确保初始 bio 独立 */ | |
BUG_ON(bio->bi_next); | |
bio_list_init(&bio_list_on_stack[0]); // 初始化 bio_list_on_stack [0] | |
current->bio_list = bio_list_on_stack; // 绑定当前进程的 current->bio_list,供递归提交中挂载新 bio | |
do { | |
struct request_queue *q = bdev_get_queue(bio->bi_bdev); // 获取 bio 目标块设备的 request_queue | |
/* | |
* 准备两个临时链表: | |
* lower:指向更底层设备的 bio | |
* same :仍针对当前层设备的 bio | |
*/ | |
struct bio_list lower, same; | |
/* | |
* 为所有下层的 requests 创建一个新的 bio_list | |
*/ | |
bio_list_on_stack[1] = bio_list_on_stack[0]; // 旧的 bio_list_on_stack [0] 备份到 bio_list_on_stack [1] | |
bio_list_init(&bio_list_on_stack[0]); // 重新初始化 bio_list_on_stack [0],收集本次递归中派生的新 bio | |
/* | |
* 递归提交当前 bio | |
* 递归过程中若产生新的 bio,会挂入 bio_list_on_stack [0] | |
*/ | |
__submit_bio(bio); | |
/* 分类新生成的 bio */ | |
bio_list_init(&lower); | |
bio_list_init(&same); | |
/* | |
* 遍历本层新生成 bio,按目标设备队列划分: | |
* 与当前 q 相同:放入 same | |
* 不相同:放入 lower | |
*/ | |
while ((bio = bio_list_pop(&bio_list_on_stack[0])) != NULL) | |
if (q == bdev_get_queue(bio->bi_bdev)) | |
bio_list_add(&same, bio); | |
else | |
bio_list_add(&lower, bio); | |
/* | |
* 组合待提交队列,优先级顺序为: | |
* 1. 指向更底层的 bio | |
* 2. 本设备队列的 bio | |
* 3. 上层递归残留的 bio 队列 | |
*/ | |
bio_list_merge(&bio_list_on_stack[0], &lower); | |
bio_list_merge(&bio_list_on_stack[0], &same); | |
bio_list_merge(&bio_list_on_stack[0], &bio_list_on_stack[1]); | |
} while ((bio = bio_list_pop(&bio_list_on_stack[0]))); // 不断从 bio_list_on_stack [0] 弹出 bio 提交 | |
current->bio_list = NULL; | |
} |
# __submit_bio_noacct_mq
提交 bio 请求,但不记录统计信息(noacct),并且针对多队列(mq)块设备子系统。
static void __submit_bio_noacct_mq(struct bio *bio) | |
{ | |
struct bio_list bio_list[2] = { }; | |
/* 取出当前进程的待提交 bio 列表 */ | |
current->bio_list = bio_list; | |
do { | |
__submit_bio(bio); | |
} while ((bio = bio_list_pop(&bio_list[0]))); /* 从列表中取出一个 bio, bio_list [0] 是主 bio 列表 */ | |
current->bio_list = NULL; | |
} |
# __submit_bio
static void __submit_bio(struct bio *bio) | |
{ | |
/* 检查和准备 bio 的加密上下文(如果有开启 inline 加密) */ | |
if (unlikely(!blk_crypto_bio_prep(&bio))) | |
return; | |
/* 检查目标块设备是否实现了自己的递交函数 */ | |
if (!bio->bi_bdev->bd_has_submit_bio) { | |
blk_mq_submit_bio(bio); /* 默认的实现(现代磁盘、普通驱动大多都用这套) */ | |
} else if (likely(bio_queue_enter(bio) == 0)) { /* device-mapper、md/raid、zram、加密等 stacking driver,进入这里 */ | |
struct gendisk *disk = bio->bi_bdev->bd_disk; | |
/* 拿到 gendisk,调用其驱动注册的 submit_bio 方法递交 bio */ | |
disk->fops->submit_bio(bio); | |
blk_queue_exit(disk->queue); /* 递交结束后,blk_queue_exit () 释放队列资源。 */ | |
} | |
} |
至此,bio 层的主要操作已经完成,下面就开始进入到 request 层。
# request 层
struct request 是块层到设备驱动的请求单元,除了包含 bio 信息,还包括调度策略标志、优先级、调度合并结果、设备资源限制(如分段数、tag)、最终完成回调等,是能被驱动 / 硬件直接下发的任务描述。驱动只认识 request,不直接处理 bio。
# 关键数据结构
在本节中,“请求” 在绝大多数情况下都是指 request 这个内核结构。
struct request 是块层(block layer)调度和驱动处理的核心 I/O 单元,每个要发往硬件的 I/O 都必须包装为 request。
/* | |
* 尽量将被引用的字段放在同一缓存行中 | |
* | |
* 如果改变了该结构体,需要确保同步更新 blk_rq_init (), 尤其是 blk_mq_rq_ctx_init () 以处理额外的字段。 | |
*/ | |
struct request { | |
/* 该 request 所属的请求队列(request_queue)。决定该 request 要投递到哪个块设备 */ | |
struct request_queue *q; | |
/* 多队列(blk-mq)下该 request 的上下文信息,标识本 request 属于哪个 software queue(通常和当前 CPU 绑定)*/ | |
struct blk_mq_ctx *mq_ctx; | |
/* 多队列 blk-mq 下的硬件队列上下文,决定本 request 实际发往哪个硬件队列 */ | |
struct blk_mq_hw_ctx *mq_hctx; | |
blk_opf_t cmd_flags; /* request 的操作码和常用标志,和 bio->bio_opf 相同,但是属于 request 级别 */ | |
req_flags_t rq_flags; /* request 的各种状态标志 */ | |
int tag; /* 本 request 在队列中的唯一标识符。用于硬件队列和 IO 调度的 tracking */ | |
int internal_tag; /* 专用于内部管理的 tag,一般在 request pool 管理 / 特殊调度时使用 */ | |
unsigned int timeout; /* 超时时间,request 最长存活时间,通常用于超时重试和调度 */ | |
/* 如下两个字段仅限内部使用,【不能】直接访问 */ | |
unsigned int __data_len; /* 该 request 总的数据长度(字节) */ | |
sector_t __sector; /* 当前处理到的扇区号,表示请求进度 */ | |
/* 挂在本 request 上的第一个 bio,request 可能由多个 bio 合并而成,这里指向链表头 */ | |
struct bio *bio; | |
/* 指向 bio 链表的末尾,用于快速追加新 bio */ | |
struct bio *biotail; | |
union { | |
struct list_head queuelist; /* 一个双向链表节点,用于将 request 加入到各种 “队列” 中 */ | |
struct request *rq_next; /* 一个单链表指针,用于一些特殊场景,例如 request 合并 */ | |
}; | |
struct block_device *part; /* request 操作的目标块设备 / 分区 */ | |
#ifdef CONFIG_BLK_RQ_ALLOC_TIME | |
/* 第一个 bio 开始分配到该 request 的时间 */ | |
u64 alloc_time_ns; | |
#endif | |
/* 该 request 被分配到这次 IO 的时间戳 */ | |
u64 start_time_ns; | |
/* I/O 被提交到硬件的时间戳 */ | |
u64 io_start_time_ns; | |
#ifdef CONFIG_BLK_WBT | |
unsigned short wbt_flags; | |
#endif | |
/* | |
* 用于块设备的统计,记录 request 最初的扇区数,值与 blk_rq_sectors (rq) 相同,在完成时不会被清零 | |
*/ | |
unsigned short stats_sectors; | |
/* | |
* 在物理地址合并(coalescing)之后,scatter-gather DMA 地址 + 长度对的数量。 | |
* | |
* 在块设备做 DMA 传输时,数据不一定连续,可能分散在不同的内存物理页面上。 | |
* Scatter-gather DMA 机制允许一次传输描述多个(物理地址,长度)对,称为 “SG 列表”。 | |
* 这样设备可以一次性高效读写多个不连续内存段 | |
*/ | |
unsigned short nr_phys_segments; | |
/* ...(省略一些可选字段) */ | |
unsigned short ioprio; /* request 的 I/O 优先级 */ | |
enum mq_rq_state state; /* 当前 request 的状态 */ | |
atomic_t ref; /* 引用计数,防止 request 被提前释放 */ | |
unsigned long deadline; /* 该 request 的调度 deadline,IO scheduler 用来判断超时顺序。 */ | |
/* | |
* hash 字段(hlist_node)只在调度器内部使用,当 request 进入 dispatch 列表后就会被移除。 | |
* ipi_list 字段只用于将 request 加入软中断(softirq)完成队列, | |
* 这发生在 request 已经从 hash 中移除(甚至 dispatch 列表中也移除)很久之后。 | |
*/ | |
union { | |
struct hlist_node hash; | |
struct llist_node ipi_list; | |
}; | |
/* | |
* rb_node 字段仅用于 io scheduler 内部,当 request 被移到 dispatch 队列时就会被移除。 | |
* special_vec 字段只有在设置了 RQF_SPECIAL_PAYLOAD 标志时才能使用,而且带有该标志的 request | |
* 不能被插入到 IO 调度器中。 | |
*/ | |
union { | |
struct rb_node rb_node; /* 用于将 request 加入调度器的红黑树结构,用于调度排序、查找 */ | |
struct bio_vec special_vec; /* 特殊 payload 时用(如 SCSI sense 数据),只有 RQF_SPECIAL_PAYLOAD 标志时可用 */ | |
}; | |
/* 提前预留了三个指针给 IO schedulers 使用,如果需要更多的话,需要动态分配 */ | |
struct { | |
struct io_cq *icq; | |
void *priv[2]; | |
} elv; | |
/* flush 请求相关的数据,保存原本的 end_io 回调和序号 */ | |
struct { | |
unsigned int seq; | |
rq_end_io_fn *saved_end_io; | |
} flush; | |
u64 fifo_time; /* FIFO 调度时的入队时间(用于排序) */ | |
/* 完成回调 */ | |
rq_end_io_fn *end_io; /* 完成回调函数。request 完成时调用 */ | |
void *end_io_data; /* 完成回调的数据(context),随 request 传递给 end_io */ | |
}; |
dispatch 队列就是等待下发给块设备驱动的 request 列表,它位于调度器和硬件之间,是高性能块层的关键缓冲区。当调度器决定该 request “可以发给硬件了”,把 request 从调度队列移出,放进 dispatch 队列。
# 执行流程
# blk_mq_submit_bio
解释几个机制:
- plug 队列机制(plug queue):
blk_plug是一个进程私有的 “临时请求缓冲区”,用于收集短时间内产生的多个请求,之后一起发给设备,提高合并和排序效率(减少寻道、提升吞吐)。- plug 队列上的 request 还没有直接进入硬件队列。
- 请求合并(request merge):
- 根据程序的局部性原理,对于块设备的访问容易出现聚集性;对于块设备来说,寻址是慢的,但是顺序读是快的,所以可以通过将多个读写请求合并的方法来减少 IO 数量,提升顺序 IO 性能。
- 所以如果当前 request 能与 plug 队列中已有的 request 合并,就直接合并。
- IO 调度器(IO scheduler):
- 如果硬件队列挂载了 IO 调度器,则请求可能被排队、排序或合并后再发到硬件队列。
- 多队列(blk-mq):
- 支持多核并发,每个 CPU 都有自己的 hardware queue,提高并发度。
/** | |
* blk_mq_submit_bio - 创建并发送 request 到块设备 | |
* @bio: bio 指针 | |
* | |
* 该函数会根据 @q 和 @bio 构建出一个 request 结构体,并发送到设备。 | |
* 但这个 request 可能不会被直接排队到硬件队列中,如果: | |
* * 该 request 能与其它 request 合并 | |
* * 我们希望把 request 放到 plug 队列, 以便未来可能合并 | |
* * 该队列上启用了 IO 调度器 | |
* | |
* 如果 bio 有错误,或创建 request 时出错,则不会入队。 | |
*/ | |
void blk_mq_submit_bio(struct bio *bio) | |
{ | |
// 获取 bio 目标块设备的请求队列指针 | |
struct request_queue *q = bdev_get_queue(bio->bi_bdev); | |
struct blk_plug *plug = blk_mq_plug(bio); | |
const int is_sync = op_is_sync(bio->bi_opf); | |
struct blk_mq_hw_ctx *hctx; | |
struct request *rq = NULL; // 用于复用或者新建的 request 指针 | |
unsigned int nr_segs = 1; // 记录 bio 会被分割成多少个 segment(bio_vec) | |
blk_status_t ret; | |
/* | |
* 如果 bio 指向的数据页面不在设备支持的 DMA 区域(如高端内存), | |
* 就需要搬运(bounce)到低端内存,否则后续 IO 无法被设备访问。 | |
* 返回 bounce 后的新 bio(可能和原 bio 相同)。 | |
*/ | |
bio = blk_queue_bounce(bio, q); | |
if (plug) { // 如果 plug 存在,尝试复用 plug 的 cached request(有助于减少频繁分配) | |
rq = rq_list_peek(&plug->cached_rq); | |
if (rq && rq->q != q) // 如果 plug 中的 request 队列与本次 bio 目标设备不同,则不能复用,置 rq 为 NULL。 | |
rq = NULL; | |
} | |
if (rq) { | |
// 如果 bio 超出设备支持的限制,需要拆分为多个 bio | |
if (unlikely(bio_may_exceed_limits(bio, &q->limits))) { | |
bio = __bio_split_to_limits(bio, &q->limits, &nr_segs); | |
if (!bio) | |
return; | |
} | |
// 数据完整性扩展准备(如 T10 DIF/DIX),失败直接返回 | |
if (!bio_integrity_prep(bio)) | |
return; | |
// 如果能与已有请求合并,则直接合并,不需新建 request | |
if (blk_mq_attempt_bio_merge(q, bio, nr_segs)) | |
return; | |
// 使用 plug 缓存的 request 进行 IO | |
if (blk_mq_use_cached_rq(rq, plug, bio)) | |
goto done; | |
// 增加队列引用计数(因为要新建 request 了) | |
percpu_ref_get(&q->q_usage_counter); | |
} else { | |
// 没有可复用 request(或不在 plug 队列),正常流程 | |
if (unlikely(bio_queue_enter(bio))) | |
return; // 队列不可用,直接返回 | |
//bio 是否超设备限制,如果超则拆分 | |
if (unlikely(bio_may_exceed_limits(bio, &q->limits))) { | |
bio = __bio_split_to_limits(bio, &q->limits, &nr_segs); | |
if (!bio) | |
goto fail; | |
} | |
if (!bio_integrity_prep(bio)) | |
goto fail; | |
} | |
// 获取一个新 request 对象 | |
rq = blk_mq_get_new_requests(q, plug, bio, nr_segs); | |
if (unlikely(!rq)) { | |
fail: | |
blk_queue_exit(q); | |
return; | |
} | |
done: | |
trace_block_getrq(bio); // 跟踪 IO 获取 request 的事件,用于 trace/ftrace/perf | |
rq_qos_track(q, rq, bio); | |
// 把 bio 里的所有 IO 数据 / 元数据都转移到 request 结构体中,request 就可以被设备识别和处理。 | |
blk_mq_bio_to_request(rq, bio, nr_segs); | |
// 如果 request 需要 inline 加密,这里分配加密 keyslot,失败时结束 bio。 | |
ret = blk_crypto_rq_get_keyslot(rq); | |
if (ret != BLK_STS_OK) { | |
bio->bi_status = ret; | |
bio_endio(bio); | |
blk_mq_free_request(rq); | |
return; | |
} | |
// 如果 bio 是 flush 类型并且插入 flush 队列成功,则后续会专门处理,无需下发到普通硬件队列 | |
if (op_is_flush(bio->bi_opf) && blk_insert_flush(rq)) | |
return; | |
/* | |
* 如果当前进程开启了 plug,则将 request 放入 plug 队列,不立即发送到硬件。 | |
* plug 队列会在适当时机(比如 plug 结束、同步写、队列满等)批量下发。 | |
*/ | |
if (plug) { | |
blk_add_rq_to_plug(plug, rq); | |
return; | |
} | |
/* | |
* 根据队列是否启用 IO 调度器(如 bfq、deadline),或队列繁忙、同步 / 异步等条件: | |
* 有调度器或队列繁忙:插入队列等待调度,并唤醒硬件队列处理 | |
* 否则:直接尝试发往硬件(无须调度,优先直发,提高低延迟场景性能) | |
*/ | |
hctx = rq->mq_hctx; | |
if ((rq->rq_flags & RQF_USE_SCHED) || | |
(hctx->dispatch_busy && (q->nr_hw_queues == 1 || !is_sync))) { | |
blk_mq_insert_request(rq, 0); | |
blk_mq_run_hw_queue(hctx, true); | |
} else { | |
blk_mq_run_dispatch_ops(q, blk_mq_try_issue_directly(hctx, rq)); | |
} | |
} |
# blk_mq_try_issue_directly
/** | |
* blk_mq_try_issue_directly - 尝试直接将 request 发送到设备驱动 | |
* @hctx: 关联硬件队列的指针 (每个硬件队列一个 hctx) | |
* @rq: 要发送的 request 指针 | |
* | |
* 如果设备当前有足够资源可以接受新 request,就直接将 request 发送给驱动。 | |
* 否则,把它插入 hctx->dispatch 队列,将来重试。插入该队列的 request 具有更高优先级。 | |
*/ | |
static void blk_mq_try_issue_directly(struct blk_mq_hw_ctx *hctx, | |
struct request *rq) | |
{ | |
blk_status_t ret; | |
/* 如果硬件队列被暂停或整个请求队列进入暂停状态,则不能下发 request */ | |
if (blk_mq_hctx_stopped(hctx) || blk_queue_quiesced(rq->q)) { | |
blk_mq_insert_request(rq, 0); // 将 request 插入 dispatch 队列,等待后续恢复后统一下发 | |
return; | |
} | |
/* 当前 request 需要调度器处理(RQF_USE_SCHED),或者无法获得 IO budget 或 tag */ | |
if ((rq->rq_flags & RQF_USE_SCHED) || !blk_mq_get_budget_and_tag(rq)) { | |
blk_mq_insert_request(rq, 0); // 插入 dispatch 队列 | |
blk_mq_run_hw_queue(hctx, rq->cmd_flags & REQ_NOWAIT); // 唤醒硬件队列调度 (有机会优先处理) | |
return; | |
} | |
ret = __blk_mq_issue_directly(hctx, rq, true); // 直接调用驱动发出 request | |
switch (ret) { | |
case BLK_STS_OK: //request 成功下发,驱动会异步处理和完成 | |
break; | |
case BLK_STS_RESOURCE: | |
case BLK_STS_DEV_RESOURCE: // 设备或驱动暂时资源不足 | |
blk_mq_request_bypass_insert(rq, 0); // 将 request 插入 bypass 队列(高优先级) | |
blk_mq_run_hw_queue(hctx, false); | |
break; | |
default: | |
blk_mq_end_request(rq, ret); // 直接结束 request,回调 end_io,设置错误状态 | |
break; | |
} | |
} |
# __blk_mq_issue_directly
static blk_status_t __blk_mq_issue_directly(struct blk_mq_hw_ctx *hctx, | |
struct request *rq, bool last) | |
{ | |
struct request_queue *q = rq->q; | |
struct blk_mq_queue_data bd = { | |
.rq = rq, | |
.last = last, | |
}; | |
blk_status_t ret; | |
/* | |
* 如果(queue_rq 返回)OK,说明请求已成功提交,不用做其他事。 | |
* 如果是错误(error,比如请求本身有严重问题),调用者会直接终止这个请求(kill it)。 | |
* 其它类型的错误(比如繁忙 busy),就把这个请求加回我们的待处理队列(dispatch 队列), | |
* 这样以后还能再试(这和我们以前的处理方式一样)。 | |
*/ | |
ret = q->mq_ops->queue_rq(hctx, &bd); // 将 request 交给块设备驱动 | |
switch (ret) { | |
case BLK_STS_OK: | |
blk_mq_update_dispatch_busy(hctx, false); // 更新硬件队列的 busy 状态 (not busy) | |
break; | |
case BLK_STS_RESOURCE: | |
case BLK_STS_DEV_RESOURCE: | |
blk_mq_update_dispatch_busy(hctx, true); // 更新硬件队列的 busy 状态 (busy) | |
__blk_mq_requeue_request(rq); | |
break; | |
default: | |
blk_mq_update_dispatch_busy(hctx, false); | |
break; | |
} | |
return ret; | |
} |
queue_rq 是一个函数指针,定义在 struct blk_mq_ops 里:
struct blk_mq_ops { | |
... | |
blk_status_t (*queue_rq)(struct blk_mq_hw_ctx *hctx, | |
const struct blk_mq_queue_data *bd); | |
... | |
}; |
它是块层(blk-mq)向具体块设备驱动程序(比如 NVMe、SCSI、virtio-blk、loop、zram、dm、md 等)下发 request 的 “驱动回调函数”。
每个支持
blk-mq的块设备驱动,都必须实现自己的queue_rq并在注册驱动时填入struct blk_mq_ops结构体。
# 参考
- https://blog.csdn.net/geshifei/article/details/119959905